
- TruEra Monitoring provides accurate and comprehensive ML model insights, with consequential data drift tracking. By examining data the way your model sees it, you can easily catch the issues most affecting your model.
- Go beyond model accuracy metrics to a much broader view of AI Quality. Root cause analysis helps you drive model performance higher and catch emerging issues faster.
- Monitor a broad range of machine learning models, no matter what your stack looks like.
Data changes all the time. Sometimes these are random fluctuations that don’t affect AI models, and sometimes small shifts can have a huge impact. As ML starts to drive significant businesses, data scientists and ML Ops teams are contending with large volumes of data flowing through a large number of models. Monitoring those models, as well as identifying, prioritizing, and addressing emerging issues, becomes harder and harder. TruEra Monitoring provides the ML model insights that help drive attention to those issues that are actually consequential and filters out the noise.
Consequential data drift identifies the issues that matter
A website team is trying to identify user fraud with an ML model by predicting a likelihood that each user is fraudulent based on examples of past good and bad user actions. The team notices the fraud scores are jumping up on average in June 2021. To understand why, they look at how features have drifted in the same time period. One such feature is the browser used, and it shows Safari usage up by 4x (an example of data drift). Suddenly there’s a flurry of questions: “Should I be worried about this? Is this the cause of my change of model scores? Am I under attack? Do I need to retrain?”
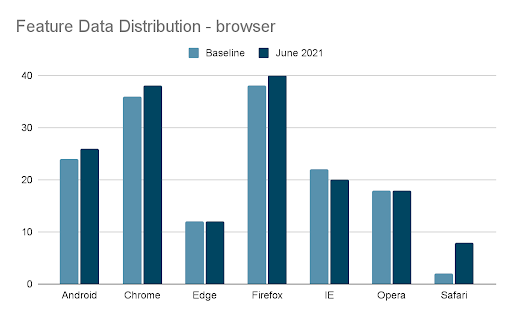
TruEra helps answer these questions with consequential drift analysis by letting you:
- Set alerts on consequential drifts
- Identify the extent of impact on the model
- Understand the future effectiveness of the model with estimated accuracy analytics
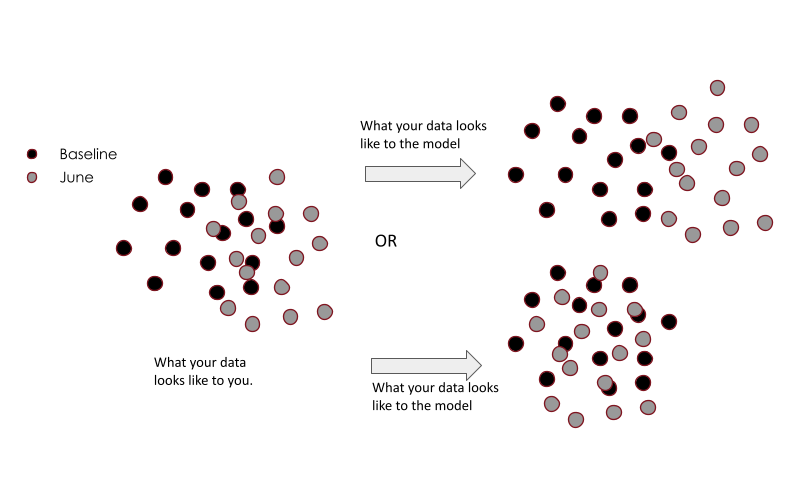
Let’s get a bit technical for a moment: TruEra analyzes your data in embedding spaces that are aligned to how your model views the data. In high dimensional data, models transform and stretch the data in a way that makes it easier to make predictions on that data. Let’s call this the “model space” as opposed to the “data space.” For example, if according to the model, all Chrome users have the same fraud rate as other browsers, a 4x jump in Safari users could be a small jump from a model’s perspective. This is also why measures like KL-divergence on the data (a standard approach to measuring data drift) can be quite ineffective and lead to false alerts. Identifying which shifts have an impact on the model or not is what we call consequential data drift. The illustration below shows how a model’s view of the data can be quite different from the data view.
Once you’re able to understand the model’s view of the data, it is also possible to understand which shifts impact accuracy the most. If the data shifts towards a less accurate region of the data, a model’s accuracy is going to reduce. We use this to estimate the accuracy of models in the absence of labels. This is a powerful tool in many use cases, including fraud, credit decisions, and marketing, where ground truth labels become available a long time after a prediction is made. TruEra’s estimated accuracy provides an early warning signal, identifying model issues ahead of time. The dotted line in the graph below measures accuracy a few months in advance of when the actual accuracy can be measured.

AI Quality Monitoring goes beyond just tracking accuracy
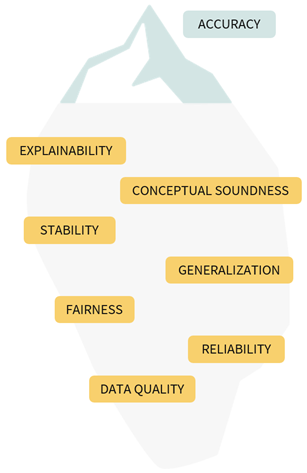
One of the key realizations as we started to build TruEra for our customers was how reliant data scientists are on train/test accuracies. Reducing the quality of models to a single number means many aspects of model behavior can get missed. Accuracy is just the tip of the iceberg.
TruEra massively expands a data scientist’s toolkit for understanding model behavior by peering under the surface and revealing deeper issues with actionable diagnostics. As an example, TruEra helps identify segments of low accuracy in the data. Once these segments are identified, these are automatically tracked to make sure that the performance in these segments are stable and don’t deteriorate over time. The illustration below shows some of the dimensions of AI Quality that TruEra helps bring to the surface. Check out this blog for a comprehensive view on AI Quality.
AI Quality encompasses much more than just accuracy.
When things go wrong with any of these metrics, TruEra enables data scientists to get to the heart of the issue on any specific metric. With one click, they can open up the TruEra Diagnostics toolbox to understand what’s going on and perform advanced root cause analysis. (More to come on the topic of TruEra root cause analysis in future posts.)
The TruEra AI Quality Platform powers rapid integrations
TruEra’s cutting edge AI Quality analytics are delivered through our platform, which makes it easy to rapidly connect to your ML stack, no matter what it looks like. The TruEra platform allows you:
- Deploy anywhere: we go to your data and models instead of them coming to us
- Evaluate any model: Work with an exhaustive list of models and data sources, even custom models
- Work with any AI Platform: Designed to work with ML platforms like Sagemaker, Azure ML, and Google AI Platform.
Here’s a diagram of how TruEra gets deployed on an Azure based AI stack, which a lot of our customers have:
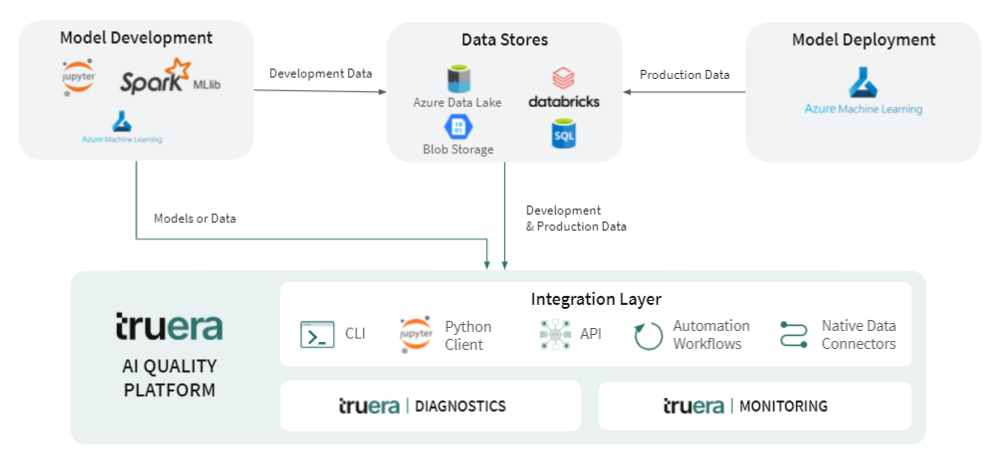
The platform level differences can be critical to the success of building a unified monitoring stack in your organization with the increasing diversity of modeling technologies. We data scientists are an opinionated bunch, and stick to the tools that we love for building models in a variety of environments. For example, with the ability to run MLLib models natively on Spark clusters in order to monitor and debug them, TruEra helps provide the exact same monitoring experience for these batch models as other model frameworks that may exist in your stack.
Authors
Shayak Sen, Co-Founder and CTO
Justin Lawyer, Chief Product Officer