
LLMs are poised to unleash a new wave of innovation in AI but there is one big problem: they tend to hallucinate, meaning that they often generate responses that are factually incorrect or nonsensical.
Retrieval-augmented generation (RAG) has become a popular framework to address this issue. Indeed, it improves the quality of LLM outputs by grounding the model on external sources of knowledge, often proprietary data. Doing so provides two main benefits: It ensures that the model has access to the most up-to-date information about a given domain and guarantees that the model’s sources are available to end-users so that its claims can be checked for accuracy.
However, RAGs don’t fully eliminate the risk of hallucinations for various reasons. First, the retrieval could simply fail to retrieve sufficient context or retrieve irrelevant context. Second, they may suffer from a lack of groundness. This means that the response generated by a RAG app is not supported by the retrieved context, but is mostly influenced by the LLM and its training data. Finally, a RAG app may retrieve relevant pieces of context, then leverage them to produce a grounded response and yet still fail to address a user query.
Because of these various types of failure modes, it is essential to evaluate RAGs for hallucinations along each edge of the RAG architecture. This can be done by using the RAG triad.
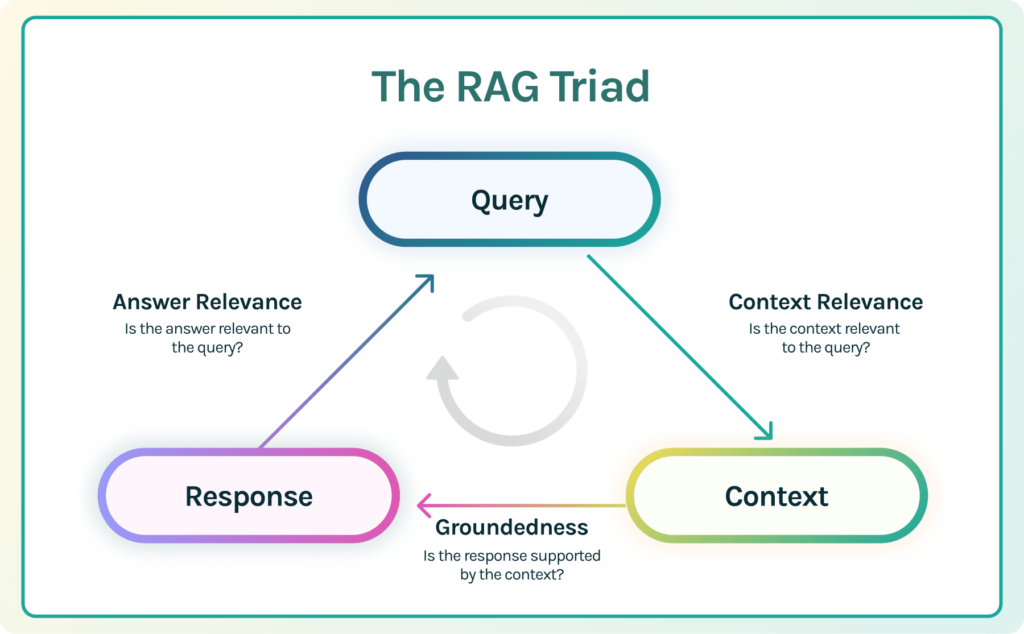
The RAG Triad
The RAG triad is composed of three evaluations: context relevance, groundedness and answer relevance. If an LLM app scores high on all of them, we can confidently assert that it is free from hallucination. Let’s review them in order.
- Context Relevance: Retrieval is the initial step in any RAG application. In order to check the quality of our retrieval, we want to make sure that each piece of context is relevant to the input query. This is crucial because this context will be used by the LLM to produce an answer and thus any irrelevant information in the context could be weaved into a hallucination.
- Groundedness: Once the context is retrieved, the LLM produces an answer. LLMs have a tendency to exaggerate, distort, or make up facts that sound correct but are not. To mitigate this risk, we divide the response into distinct claims and independently search for evidence that supports each within the retrieved context. Groundedness measures the extent to which the claims made by the LLM can be attributed back to source text.
- Answer Relevance: Finally, the original question must still be helpfully answered by our response. We can confirm this by evaluating the relevance of the final response to the user input.
Conclusion
By leveraging the RAG triad for evaluating a rag app, make a nuanced statement about our application’s correctness and assert that his application is verified to be hallucination free up to the limit of its knowledge base. Put simply, if the vector database contains only accurate information, then the answers provided by the RAG are also accurate.
If you’re currently building a RAG app, use the RAG Triad to ensure that it is free form hallucination!