
How do you ensure your model is fair from start to finish?
In the first blog post of this series, we discussed three key points to creating a comprehensive fairness workflow for ensuring fairness for machine learning model outcomes. They are:
- identifying bias (the disparate outcomes of two or more groups)
- performing root cause analysis to determine whether disparities are justified, and
- employing a targeted mitigation strategy.
We then delved into the ways in which a model could even become biased in our second post of the series.
But how do these translate the intention to be fair into a machine learning model that is fair, and continues to be fair over time?
Data scientists can create workflows that ensure ongoing fairness. Here, we highlight some aspects that are critical to bringing a fairness workflow to life:
- Making fairness intentional, avoiding misuse of fairness as a concept by clarifying what is unique about the workflow.
- Supporting root cause analysis to dig into the sources of any biases and whether they are justified.
- Regular reporting to relevant stakeholders, highlighting key analyses and results over time
For the following workflow steps, we are going to reference the TruEra Diagnostics solution and use screenshots from that solution to illustrate how the workflow can be created. However, these steps are intended as a general explanation– let’s reimagine a fairness analysis workflow using the tools we have.

A fairness workflow involves careful consideration at each step of a model’s life cycle.
Making fairness intentional
It is critical that fairness analyses are not misapplied. It doesn’t make sense to consider two arbitrary segments when comparing fairness; the model might be totally justified in favoring one segment over another. For example, a “high debt” segment vs. “low debt” segment in a credit approval context would be a justified example for variable treatment. A lack of intention can lead to indiscriminate use of a fairness toolkit without thinking through the why and how.
Instead, it’s critical to determine whether a segment is “protected” by legal or regulatory standards. To address this, it is important to explicitly mark segments as protected prior to commencing a fairness workflow. In TruEra Diagnostics, the segment management pages allow users to do this. Although ad-hoc fairness analysis is still allowed on any arbitrary segments, a clear warning and guidance on how to set the segment as protected is displayed prominently in both the evaluation and report flows.

Setting protected segments in advance makes a workflow intentional.
If you are using a solution for managing fairness, the user can focus on continuous monitoring of fairness metrics for protected segments. Ideally, you would be able to quickly review features that are driving any sources of disparity, as seen in the figure below.
If you are not using a solution and instead are setting up your own monitoring, you would need to regularly run your analytics for the protected segments to ensure that the model outputs remain fair over time. The frequency and consistency of the reviews are important, so that any drift can be identified and resolved quickly. Today, fairness reviews of in-production models are often not conducted, or conducted so infrequently that it increases the risk of poor results and business risks for the organization.

Once protected segments are set, fairness can be continuously monitored, saving time over creating ad hoc reviews with arbitrary review windows.
Root cause analysis– the key to rapid mitigation
Once a disparity is identified, the root cause analysis of identifying feature-level contributors to disparity can help both the model developer and validator hone in on how the bias crept into the ML model, which we discussed in our previous blog post, “How did my ML model become unfair?” Examining the key contributing features can then help determine whether a bias is justified and also guide a choice of a mitigation strategy.
Let’s make this clearer with a concrete example. Suppose we’re training a model on a dataset similar to UCI’s Adult data. The model uses census data to predict whether a household’s annual income is greater than $50,000. The dataset contains some demographic features such as gender and race, but these features are not provided to the model because the developer doesn’t want the model to use protected attributes to make predictions. The developer decides that the disparate impact ratio (the ratio between the proportion of men vs. women who are assigned a positive outcome) is the appropriate fairness metric to use for this problem.
Upon training the model, the developer finds that the women are disadvantaged by the model as compared to men, assigning them lower scores:

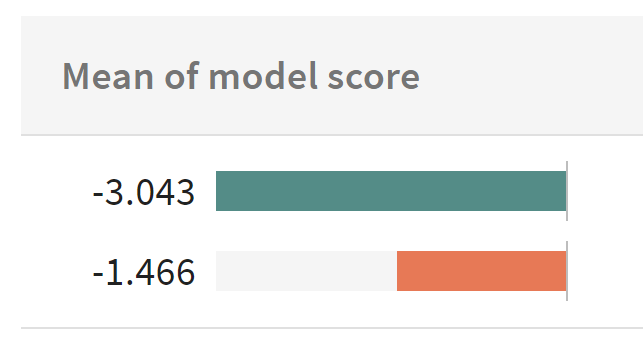
IThe first step in root cause analysis – finding a disparate impact on a protected group.
The developer is puzzled as to why this is occurring, and performs a root cause analysis to dig into the feature-level contributors of the disparity. In essence, this analysis looks at the core drivers of higher model scores for men as compared to women. It then becomes apparent that the “marital status” feature is the top-most contributor to a disparity between men and women:

Digging deeper and finding a driver of disparity: marital status.
The developer pokes further into “marital status” and notices that in the test data, women report their marital status as “single” at a much higher rate than men, despite marriage rates being about equal across gender in the real world. The developer then confirms with a model validator that this data anomaly is unexpected, and works to resample the data such that men and women report a marital-status of “single” at roughly the same rate. Their mitigation strategy did not have to be blind with the knowledge of the key contributing factor, and with the resampling approach, women are only marginally disadvantaged compared to men using the disparate impact ratio metric:

After the test data issue is identified and the data is resampled, the impact of the disparity is mitigated.
Justifiability and the importance of “human in the loop”
A key component of any fairness workflow is justifiability. We found that protected features, such as gender, are sometimes correlated with features, like income, that a reasonable model can and should use. In these cases, the model should not be declared unfair immediately. It may be using the income feature in a sensical way, without creating a proxy of gender. A human needs to be in the loop, as an expert can disentangle whether the model’s behavior is reasonable or not.

To capture this idea of reasonable behavior, it is important for a model validator or data scientist to be able to “justify” a model bias. In this workflow, a human can enter the loop, systematically review the bias, and determine whether the model is still fit for production. We recommend that a fairness report on any model contains an explicit section for this kind of expert analysis, which gives space to comment on the justifiability of any bias that is present.

Image by Author. An example of how an expert can provide a review of a fairness assessment to identify it as justified or not justified.
Regular reporting: satisfying stakeholders and compliance requirements
Multiple organizational stakeholders typically have an interest in the fairness of machine learning models. Due to the importance and sensitivity of potential fairness issues, reporting and communication of a model’s fairness is critical. Diagnostic reports should enable data scientists and model validators to easily share and present reports to peers and other business stakeholders. These reports should represent singular snapshots of a complete workflow and allow users to understand and dissect the components of a fairness analysis. Below is a sample report from TruEra, but any organization can create their own report using a combination of ad hoc monitoring analytics, an integrated business intelligence solution for visualizations, and a template using either slide or word processing solutions.
Similar to the fairness monitoring analytics themselves, reporting should happen on a regular basis, particularly in those industries, like financial services, that have regulatory compliance requirements.

Fairness reports allow data scientists, model developers, and business stakeholders to easily communicate about a model’s fairness.
Language and visualization: the devil is in the details
You may have noticed that we have chosen the term “fairness workflow” instead of a “bias workflow.” This is intentional. Our team has invested quite a bit of time in debating nuanced questions about the language and visual elements of a fairness workflow. The abstract nature of fairness places a premium on clear communication with the user.
For this reason, the workflow was renamed to Fairness rather than Bias. “Fairness” is fundamentally about ensuring that an algorithm meets a societal standard; “bias” led to confusion due to term overloading in machine learning. Furthermore, “fairness” implicitly communicates the positive intention of the workflow.
Putting it all together
This series has covered a lot of ground and summarized our complete fairness workflow. We discussed the theoretical, practical, and societal underpinnings of fairness. We also argued that a complete fairness workflow will identify bias, perform a root cause analysis to determine whether the bias is justified, and then employ a targeted mitigation strategy. We also stepped back and uncovered how AI/ML models can become unfair in the first place.
Then, to bring this to life, we bridged these concepts with human-centered design. A workflow should be intentional and keep room for a human-in-the-loop while still automating the process. A clear, automated workflow will help any developer, validator, or business stakeholder who interacts with ML models. It’s also important to point out that while solutions exist for these workflows, with time, effort, and intention they can also be created from existing tools and incorporated into existing processes. As AI becomes a greater part of our lives, ensuring that models are developed with fairness in mind and monitored to ensure ongoing fairness is a huge priority for both business and society.
Authors: