
What is an explanation and why do ML models need them?
Machine learning is arguably the most powerful statistical correlation identification engine available to us. Models learn to encode complex relationships between inputs and outputs, catching what humans can often miss. These models thus have the power to revolutionize how we make key decisions— but they are far from perfect, and can latch onto spurious correlations, change over time, or replicate human biases.
As ML is more widely used and deployed, it’s imperative that humans can trust these algorithms. Why does the model behave a certain way, or why did it make a specific decision? Humans cannot easily make sense of the inscrutable mathematical transformations that the model is performing, and as a result, explainability has become a key area of research in ML.
Not all explanation frameworks are equal. In this blog post, we’ll dive into what constitutes a good explanation framework and underscore the importance of getting it right. We’ll also talk about the consequences of using a poor explanation framework to make sense of a model. Later in this series, we’ll compare our own QII explanation framework with other contemporary solutions and see how they meet our requirements for a good framework.
What constitutes a good explanation framework?
In 2016, we realized the connection between two disparate streams of approaches for understanding complex systems: causal testing (for understanding natural systems) and cooperative game theory (for understanding voting systems), and how the confluence of the two can be adapted to create a rich set of tools for understanding machine learning.
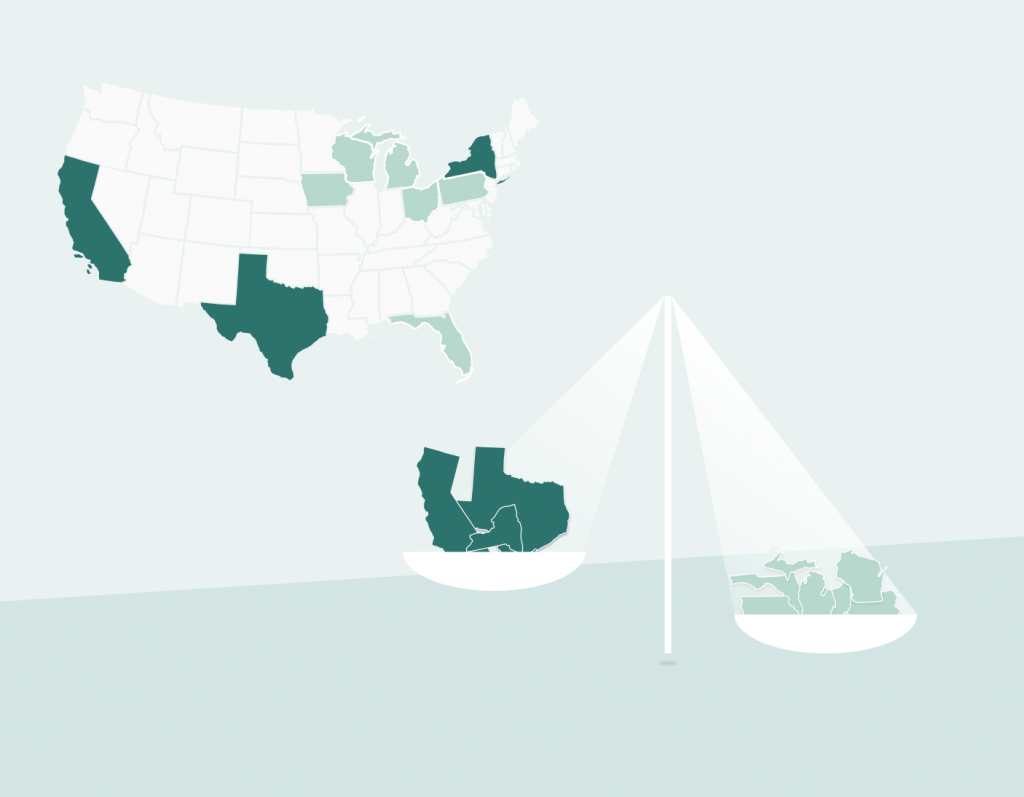
Reflect the “power” of a feature
Let’s consider the setting of the US Presidential election. If every state’s vote is an input feature, then an election is a linear classification model. For any state, the impact of the state on the election not only depends on the number of electoral college votes assigned to the state, but also how these states typically vote and whether voting can make a difference. As a result, the largest states (California and Texas) aren’t often the most important states that determine the outcome of the election. Rather, the swing states, such as Pennsylvania and Florida, carry more power in deciding the final outcome. Similarly, the most important features for a linear classifier trained using machine learning aren’t necessarily the ones with the largest coefficients.

Capture causal influence
An important part of genetic studies is to understand which genes cause which conditions. In order to precisely identify these causal effects, scientists break correlations between different genes by knocking out certain genes to examine the impact on the specific conditions. While machine learning models are simpler than biological models, many of the same ideas as causal testing in scientific systems apply. One can understand the behavior of a model by systematically breaking correlations and examining the outcomes of models.

Answer a rich set of queries
Given that we have the mechanisms to explain a wide range of complex systems, it is important that explanations are answering the correct question. An explanation of why a certain candidate won an election can be quite different from why they received 306 electoral college votes. While the latter is heavily influenced by populous states, the candidate may have won the election because of smaller swing states that have outsized importance compared to the number of its electoral votes. Similarly, the explanation for probability outcomes can be quite different from an explanation of classification outcomes for the same model. Even beyond classification and scoring outcomes, one could be interested in comparative explanations (why person A got a positive classification and not B), or group disparity (why the group of men got higher scores compared to the group of women in the model).
Be accurate
Unlike many other machine learning problems, explanation methods aren’t accompanied by some notion of ‘ground truth’. It’s difficult to know when explanation methods make large and systematic mistakes without carefully thinking through what constitutes a good explanation. Even defining correctness requires a significant analytical undertaking to define the properties satisfied by an acceptable explanation. Because of how easy it is to get explanations wrong, it is critical to set strict criteria for correctness for explainability methods and evaluate them against these criteria.
In summary, we posit that explanations need to meet the following four criteria:
- Explanations must reflect the “power” of a feature. Put simply, the model outcome must be attributable to each input feature and how it guides a decision.
- Explanations must capture causal influence between individual and sets of inputs and the final model outcome.
- Explanations must be able to answer a rich set of queries. What are the explanations trying to convey about the model?
- Explanations must be accurate. Explanations can meet the first three principles without being precise or correct.
What happens when we get it wrong?
An essential part of an explanation is answering the right question. As was the case with the election example before, if the explanation is answering the wrong query (e.g. raw score vs. classification decision), this can have vast implications on the explanation quality. It’s the equivalent of suggesting that California was the primary reason for the 2020 election results– while it certainly contributed to Joe Biden’s victory, it was not the state that solidified his win. In this way, misidentifying the correct query can lead to completely incorrect explanations of a model decision.
Another part of an explanation query is the comparison group. The comparison group serves as the baseline or “normal” distribution of data that the model performance is being compared against [1, 2]. A comparison group can be set to a single individual, a segment of the population, or to the entire dataset, and choosing the right comparison group for the given use case can make a significant difference to the model explanations– “Why was Jane denied a loan relative to those accepted?” is fundamentally different from “Why was Jane denied a loan compared to John who was approved?” and even “Why was Jane denied a loan compared to other women?”. In this example, comparing against the set of individuals who were accepted focuses only on the aspects of the prediction that make an individual different from the group that was accepted, rather than identifying the specific features that caused Jane’s application to get rejected versus John’s accepted application. Similarly, the size of the comparison group is critical to calculating a correct explanation, as choosing an incorrect sample size can lead to statistically biased results and therefore consistently inaccurate explanations– even if the comparison group itself is chosen correctly.
Finally, the interpretation and explanation literature is often disconnected from the consumer of the explanation [3]. Explanations are only useful if they are understandable to the right end-user. While a data scientist who built a model might be able to parse 150+ feature-explanations at a local and global level, non-technical users will have difficulty making sense of them. As a result, we need to develop abstractions for non-technical users to understand the model at a higher level, and work towards a future where ML models can be safely deployed and regulated without their current opacity.
Explanations are often thought of as the final step in a model development process, where once a model is satisfiably performant, we then attempt to understand it. But we believe that explanations are often not an end in themselves, but rather, a mechanism to test and debug models throughout model development. Local explanations are often a starting point in debugging why a model makes a certain mistake, and identifying how explanations change when comparison groups are set to individuals in protected classes can expose bias within models. Robust and accurate explanations are critical to almost all part of the model development pipeline.
The way forward
As ML is more widely adopted, it will transform society and the way we make decisions. But in order to better understand and thus trust these models, we need to explain them. And we need to explain them correctly.
We’ve outlined a set of principles that explanation frameworks should meet, and talked about the harms of using explanation techniques that do not meet these requirements. Back in 2016, we were among the first to think about explanations from this lens– and since then, the ML community has started to agree, with more work being done to build on this line of thinking. In our next post, we’ll talk about our QII explanation framework and how it has the power to provide the explanations we need to trust algorithms.
Authors
Anupam Datta , Co-Founder, President, and Chief Scientist
Divya Gopinath, Research Engineer
Shayak Sen, Co-Founder and Chief Technology Officer
Illustrations
Mantas Lilis, Designer