
Amid the excitement surrounding large language models (LLMs) since the release of ChatGPT, Claude, and Bard, business and tech executives are understandably wondering, “Is this hype, or a truly transformational technology?” And If it is indeed transformational, “How can I capture its business value while mitigating its potential risks?”
Several key indicators confirm that LLMs are game changers. First, we are observing massive adoption: ChatGPT reached 100 million users two months after launch, which has led to the rapid democratization of AI. Indeed, no data science degree is needed to use this app, because user queries and responses are in “plain English.” Second, these models are incredibly versatile. They can handle a wide range of natural language processing (NLP) use cases, including text generation, text summarization, text extraction, search, and text rewriting. This is a stark contrast to “classic” machine learning models which were notoriously narrow in applicability.
This recent progress is remarkable, but also creates unique challenges. Indeed, it is now well established that LLMs are prone to “hallucinations,” may exacerbate human bias, struggle to produce highly personalized outputs, and might generate copyright-violating material or harmful content. To address these challenges, we argue for the introduction of an observability layer into the LLMOPs stack. An AI observability layer enables ML teams to evaluate, track, debug, and monitor LLM-powered apps, leading to higher quality and trustworthiness.
To make this case, we start by introducing a reference architecture for an LLM-powered chatbot, a popular use-case in the industry. Then, we explain how to approach quality evaluation for such apps. Finally, we discuss which capabilities an observability layer needs to support evaluation and maintenance of quality of LLM-powered applications from development to production. In this last section, we introduce TruLens – an open source tool to evaluate and track LLM-powered apps.
LLM-powered chatbot architecture
The scenario: a data science team is tasked with building an LLM-powered chatbot to support financial advisors at a large bank. The data scientists have various options to develop such an app. They can train a large language model from scratch and then use company data to refine it, but this would be really expensive. According to some estimates, Open AI has spent around $100 million to train GPT-4. They could also fine-tune existing open-source models. However, this does not work well on small datasets because LLMs need at least 10 occurrences of each piece of information in the training set in order to remember it. Fine-tuning also tends to be expensive, since it requires some level of re-training. Plus, pasting all of the company’s documents into a proprietary LLM would not work either, because of context windows limitations – the GPT-4 model can only process around 50 pages of input text before performance degrades significantly.
In this context, the most sensible approach is to use an existing LLM, condition it on proprietary data, and do some clever prompting, an approach known as Retrieval Augmented Generation (RAG), where the model retrieves contextual documents from an external dataset as part of its execution.
Here is a visualization of the LLM-powered chatbot architecture using retrieval augmented generation:
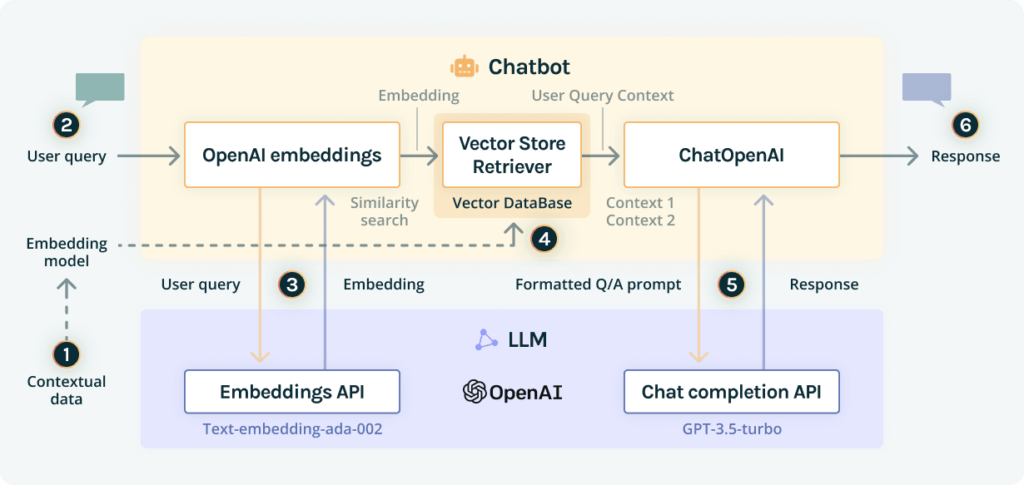
To produce a response, the LLM-powered chatbot goes through a six-step process:
- Step 1 – data embedding: at this stage, company documents are broken into chunks, passed through an embedding model, then stored in a vector database.
- Step 2 – query request: A financial advisor asks a question about wealth management. For instance, “What are the bull and bear cases for the future performance of Apple stock?”
- Step 3 – prompt construction: using an orchestration framework (e.g., Langchain or LLamaIndex), the chatbot requests an embedding API (e.g. ext-embedding-ada-002) to embed the question, and gets back the embedding for the user query.
- Step 4- prompt retrieval: Using the embedding query, it runs a similarity search across a vector database and identifies the two most similar pieces of context by cosine similarity (i.e., it measures the similarity between two vectors of an inner product space), and returns chunks of documentation: context 1 and context 2.
- Step 5 – prompt execution: the chatbot takes the user query and the retrieved pieces of context to format it into a single prompt and sends it to the chat completion API (e.g., GPT 3-5), asking to answer the user query using these pieces of context.
- Step 6 – query response: This answer is shared with the financial advisor.
Quality is in the eye of the domain-knowledge expert
We asked “What are the bull and bear cases for the future performance of Apple stock?” to ChatGPT and here is an excerpt from the response we received:
Bull Case for Apple Stock:
- Strong Product Portfolio: Apple has a history of successful product launches, including the iPhone, iPad, Mac, and Apple Watch. The bull case suggests that Apple will continue to innovate and introduce new products that capture market demand, driving revenue and profitability.
Bear Case for Apple Stock:
- Saturation of iPhone Market: Critics argue that the global smartphone market is becoming saturated, making it challenging for Apple to maintain the same level of growth it has experienced in the past. Slowing iPhone sales could impact Apple’s overall revenue and profitability.”
But is this a high-quality answer? If not, what could be done to improve its quality? These are arguably the most important questions to unlock the potential of LLMs in business environments, particularly in high-stakes domains where answers could have a deep effect on people’s life chances in areas such as banking, healthcare, and law. Let’s unpack these questions with a simpler example to understand how to approach quality evaluation.
At its core, an LLM-powered chatbot is a prediction machine that produces a reasonable answer to what one might expect a human expert to write. It has acquired this knowledge after being trained on vast amounts of human-generated data available online or through other data sources. If we ask a very “common” question, there are probably enough pieces of information in the training set to get a reasonable answer that most users can directly assess because they have some level of knowledge on this topic or access to trusted sources of information.
For example, if one asks ChatGPT, “What is the capital of France?”, there is a high probability that Paris is the right answer, based on its training data set, and most people probably know this fact as well, so can easily verify that the answer is correct. This also works with open-ended questions, such as “What were the causes of World War II?” Again, there are enough relevant pieces of information in its training set to produce a high-quality answer, most people probably studied the topic at school, and if someone does not know, they can always turn to history books or other trusted sources for confirmation.
However, ChatGPT is unlikely to produce a reasonable answer to a question if it has no access to relevant pieces of information. One would still get its most probable guess, but it might just be a hallucination or an irrelevant answer.
Returning to our initial question about Apple, it seems like a high-quality answer to me – a non financial expert, doing some investment in my spare time. A financial advisor at a leading bank would probably expect stronger arguments, and by leveraging proprietary financial data held by the bank, the chatbot could probably produce a better answer. Yet, a very seasoned financial analyst who has invested in Apple stock for the last 10 years would probably have even higher expectations and we would need to capture her feedback to further improve the quality of the chatbot outputs.
You get the point: quality evaluation is a function of contextual data relevance and domain-knowledge expert feedback. By modeling this relationship, we can then programmatically apply it to scale up model evaluation. This can be done by adding an observability layer into an LLMOPs stack.
The observability layer
The observability layer allows one to manage AI quality throughout the LLM-powered app lifecycle, optimizing language models for specific contexts and user expectations. It includes capabilities to evaluate, track, debug, and monitor the performance of large language models at scale.
Here is an updated visualization of the LLM-powered Chatbot Architecture with the observability layer:
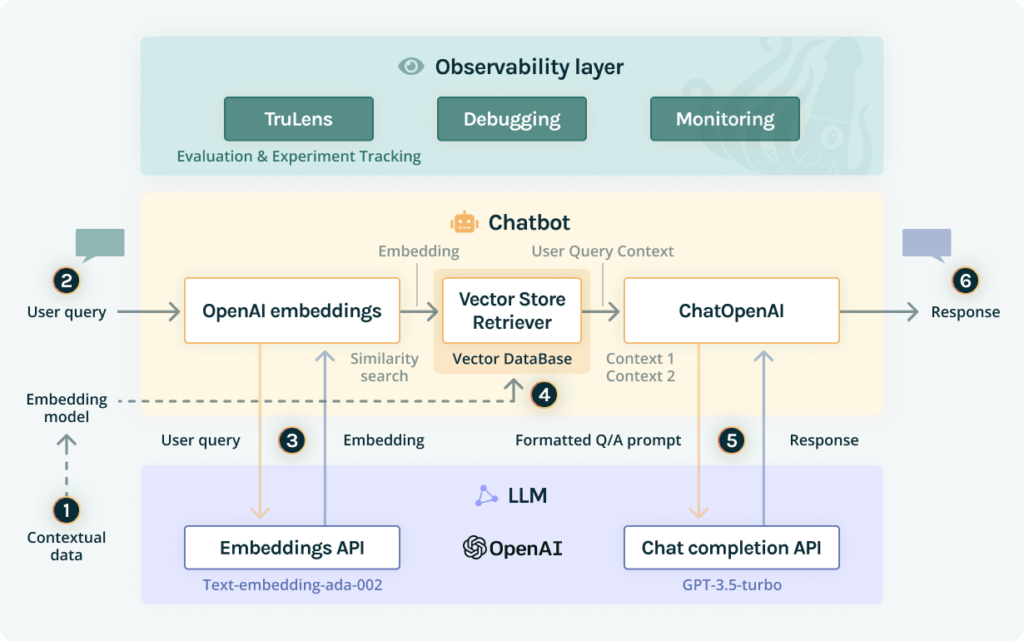
TruLens offers an extensible set of feedback functions to evaluate and track LLM-powered apps and thus constitutes the first component of this layer. A feedback function takes as input generated text from an LLM-powered app and some metadata, and returns a score. Feedback can be explicit (e.g., thumbs up/thumbs down or user reviews) or implicit (e.g., a sentiment analysis of user comments). They can be implemented with simple rule-based systems, discriminatory machine learning models, or LLMs.
Using TruLens one can assess quality requirements such as relevance or toxicity; identify areas of weaknesses of the app to inform iteration on prompts, hyperparameters, and more; and compare different LLM chains on a metrics leaderboard to pick the best performing one.
The way forward
The advent of LLMs represents a paradigm shift in the AI industry and is poised to unleash a new wave of innovations. To empower developers, a new LLMOps stack is quickly emerging before our eyes. It includes tools for data preprocessing and embedding, prompt construction, retrieval, and execution as well as orchestration frameworks. But there is an observability gap that must be addressed to unlock their full potential.
TruLens fills this critical gap. It meets an important need and is rapidly evolving based on feedback that we receive from our clients and partners. At the moment, additional debugging and monitoring capabilities are being added to it, so that it will soon meet the full range of AI Observability requirements for LLM-powered apps. We’re dedicated to making LLMs trustworthy and will regularly update you as we make progress. Please reach out if you have any feedback or suggestions through our slack community.