
Large language models (LLMs) are gaining rapid adoption across industries, powering experiences that might even look magical – summarizing complex legal documents, answering complex financial questions or even generating code for software developers at unprecedented speed. Designed to predict and generate plausible language, after being trained on a massive amount of text data, LLMs can handle a wide range of natural language processing (NLP) use cases, including text generation, extraction and summarization, as well as search.
This recent progress is remarkable, but also creates unique challenges, chief among them is their propensity to hallucinate; that is giving very confident answers that are factually or logically incorrect. Many business and tech executives are understandably wary of implementing LLMs in their products and workflows because of this risk. Yet, various efforts are underway in the industry to address their concerns and build more trustworthy LLM-based applications. A prevalent method is to implement a retrieval-augmented generation framework where LLMs are fed with contextual data stored on an external knowledge base. While valuable, this framework does not fully address the problem.
In this article, we explain why LLMs are prone to hallucinations, present the limitations of the retrieval-augmented generation framework wrongly perceived as a single bullet, and offer a complementary approach to effectively mitigate hallucinations from LLM-based apps.
Hallucination is a feature, not a bug
At their core, LLM-powered chatbots such as ChatGPT, Claude, and Bard are simply prediction machines that produce reasonable answers to user queries by leveraging the knowledge that they acquired after being trained on vast amounts of human-generated data available online or through other data sources.
Powerful as they are, current AI chatbots suffer from several limitations. For one thing, their knowledge is static, meaning that it covers a delimited space and time. For instance, regular ChatGPT is trained on data from events before September 2021, so anything that happened after can’t be accessed. Second, they are stateless – they treat all user queries equally and save no information from prior queries. Therefore, their answers depend only on the data and parameters that were sent in the payload. Further, they are trained for generalized tasks. Indeed, AI chatbots know a broad range of facts about a lot of topics but don’t have deep expertise on any particular one. This makes it difficult to leverage them for use cases requiring highly contextual knowledge. Finally, they don’t have any understanding of the underlying reality that language describes. All they can do is to generate words with high-statistical probability but they don’t know what they mean.
LLM-powered apps have no means to know whether or not their outputs are incorrect or nonsensical, let alone the ability to inform users about the overall quality of their outputs (e.g. accuracy, groundness, toxicity, fairness, etc). Under these circumstances, one should always assume that they may hallucinate and implement tools and processes to mitigate this risk.
Retrieval-augmented generation can only take you so far
A popular approach to reduce hallucinations from LLM-powered apps is to provide them with additional contextual data stored on a vector database; an approach also known as retrieval-augmented generation (RAG). This framework improves the quality of LLM-outputs by grounding the model on external sources of knowledge, often proprietary data, to supplement the LLM’s internal representation of information.
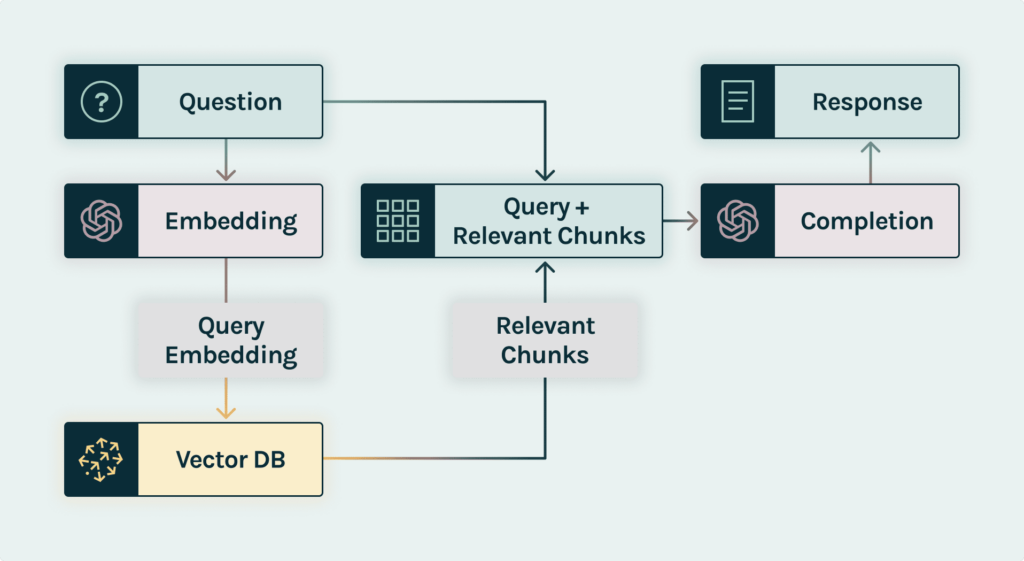
Here is a fictional scenario: Imagine that you have just started as an underwriter at a leading insurance company. You ask “how to calculate car insurance premiums for seniors?” to the internal AI chatbot. As opposed to ChatGPT, which has no particular expertise on insurance policy, this chatbot has access to a vector database that includes the company’s policies on car insurance. After running a similarity search across the vector database, the retriever identifies the most similar pieces of context based on their embedding distance to provide to the chat completion model.
Implementing RAG provides two main benefits: It ensures that the chatbot has access to the most up-to-date information about car insurance policies and guarantees that the model’s sources are available to underwriters so that the chatbot claims can be checked for contextual relevance.
Here is an visualization of the RAG LLM-powered Chatbot Architecture:
However, the most similar pieces of context may still be irrelevant to the user query. To continue with our car insurance example, here is an excerpt from the response we received from our RAG AI chatbot:
- “when calculating car insurance premiums, you should consider the following factors: age, occupation, annual mileage, address, medical history, body mass index and tobacco use”.
If the first five variables are sensible, the last two are clearly irrelevant. It seems that the chatbot mixed documentation about car and health care insurance premiums. Put simply, it partially retrieved the wrong context.
Another potential issue that may arise with the RAG framework is lack of groundness. This happens when the response generated is not supported by the retrieved context. After a quick investigation, one may realize that the response generated was more influenced by the LLM and its training data than data stored in the vector database. This can be dangerous because the large corpus used in pre-training is unverified, often irrelevant and inappropriate for your application. While we want to leverage the learnings about language and styles from the model’s pre-training, it’s critical that the factual information used comes from sources that we have verified and trust.
Finally, a RAG chatbot may retrieve relevant pieces of context, then leverage them to produce a grounded response and yet still fail to address a user query. In our running example, the response generated is rather general while we asked how to calculate car insurance premiums for a specific demographic.
Because of these various types of failure modes, it is essential to continuously evaluate RAG LLM-powered apps across their lifecycle (see figure 1). This can be done by adding an observability layer to your RAG LLM experiments.
Evaluating RAGs with Trulens
One is unlikely to get a fully functioning LLM-based app from the first attempt. Instead, she should build an initial version, iterate with prompts, parameters and fine-tuning. Throughout this process, she should systematically track and evaluate the overall quality and performance of her app using an observability tool. This layer is the key part of the emerging LLMOPs stack enabling data scientists to manage AI quality throughout their app lifecycle.
TruLens is an observability tool, offering an extensible set of feedback functions to track and evaluate LLM-powered apps. Feedback functions are essential here in verifying the absence of hallucination in our app. These feedback functions are implemented by leveraging off-the-shelf models from providers such as OpenAI, Anthropic or HuggingFace. This provider is easily set up with TruLens:
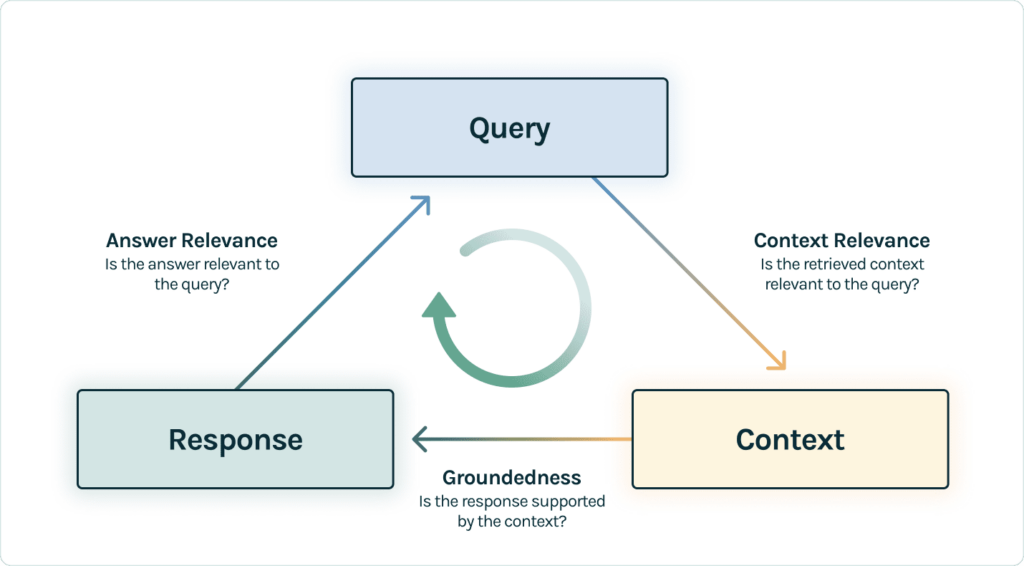
After we’ve initialized our model provider, we can select the evaluators we’d like to use. TruLens provides three particular tests to evaluate hallucination: context relevance, groundedness and answer relevance.
Let’s go through each of these to understand how they can benefit us.
Context Relevance
The first step of any RAG application is retrieval; to verify the quality of our retrieval, we want to make sure that each chunk of context is relevant to the input query. This is critical because this context will be used by the LLM to form an answer, so any irrelevant information in the context could be weaved into a hallucination. TruLens enables you to evaluate context relevance by using the structure of the serialized record. You can see this below with the helper method: select_source_nodes().
Groundedness
After the context is retrieved, it is then formed into an answer by an LLM. LLMs are often prone to stray from the facts provided, exaggerating or expanding to a correct-sounding answer. To verify the groundedness of our application, we should separate the response into separate statements and independently search for evidence that supports each within the retrieved context.
Answer Relevance
Last, our response still needs to helpfully answer the original question. We can verify this by evaluating the relevance of the final response to the user input.
By reaching satisfactory evaluations for this triad, we can make a nuanced statement about our application’s correctness; our application is verified to be hallucination free up to the limit of its knowledge base. In other words, if the vector database contains only accurate information, then the answers provided by the RAG are also accurate.
Putting it together
After we’ve defined these evaluators, we can now leverage them in our application by providing them as a list.
Now we can proceed with confidence and evaluate each time our application is run and quickly identify hallucinations when they occur.
Conclusion
Despite the hype, LLMs are creating business value and, as a result, are rapidly being adopted across industries. Their natural language understanding is quite remarkable and likely to improve in the near future. Yet to maximize their benefits, one needs to acknowledge their existing limitations, starting with their propensity to hallucinate.
However, this is not a fatal flaw and solutions are starting to emerge. Indeed, as argued in this piece, augmenting LLMs with long-term memory through retrieval-augmented generation frameworks and continuously evaluating them with observability tools goes a long way in mitigating this risk.
If you’re currently building an LLM-powered app, try Trulens to ensure that it is trustworthy!
This blog was co-authored by Shayak Sen and Lofred Madzou.