
The Time to Minimize AI Bias is Now
Bias in Machine Learning is no longer a theoretical concept debated in ivory towers; it is a real-world challenge that demands our attention. It’s filling our companies with Jareds that play lacrosse, penalizing graduates of women’s colleges, and featured on Last Week Tonight with John Oliver. In order to really address bias, we, as data scientists, need better tools to understand when bias is happening and what to do about it. This article is a practical guide to evaluate and debug unfair bias by understanding the root causes.
ML-based applications are increasingly being deployed in various sectors such as online advertisements and credit risk decisioning — however, these ML models may create unfair racial and gender biases. Identifying bias in ML systems before they reach production is a core business and regulatory imperative.
Lately, many regulators have passed legislation that requires organizations using ML systems to assess and report the fairness of their ML models. In 2021, the New York City Council passed a first-of-its-kind bill that requires hiring vendors to conduct annual bias audits of automated employment decision tools, the State of Colorado signed Senate Bill (SB) 21-169 into law to protect consumers from unfair discrimination by big data systems.
Yet, the most ambitious policy response has come from the European Union where the EU Artificial Intelligence Act – a comprehensive regulatory proposal which classifies all AI systems under distinct categories of risks and introduces specific obligations for those labeled as high risk and outright bans AI applications deemed as “unacceptable risk”. The White House has also signaled more regulations are coming with the AI Bill of Rights.
3 Steps to Minimize Bias – Credit Processing Example
Using a credit processing example, we will walk through how to:
1. Evaluate model fairness. Here we will focus on group fairness.
2. Diagnose potential root causes of disparate impact.
3. Improve fairness using techniques including feature removal and class rebalancing.If you’d prefer to follow along in Google Colab, you can do so here: Open in Colab.
Evaluate Disparate Impact
For this example, presuppose that we’ve already added a project, data splits and model to TruEra. To measure the fairness of that model, we need to add segment groups and set the protected segment; this is the segment of the data on which we wish to measure fairness.
Then we’ll add a fairness test for that protected segment to examine Disparate Impact. Disparate Impact compares the proportion of individuals that receive a positive output for two groups: an unprivileged group and a privileged group.
In this test, we’ll use regex to apply the test to all data splits. We’ll also use the all_data_collections and all_protected_segments flags to apply it to all data collections and protected segments. The industry standard is the four-fifths rule, if the unprivileged group receives a positive outcome less than 80% of their proportion of the privileged group, this is a disparate impact violation.
Now we can view the results of the Impact Ratio test in the TruEra web application or by using get_model_test_results():
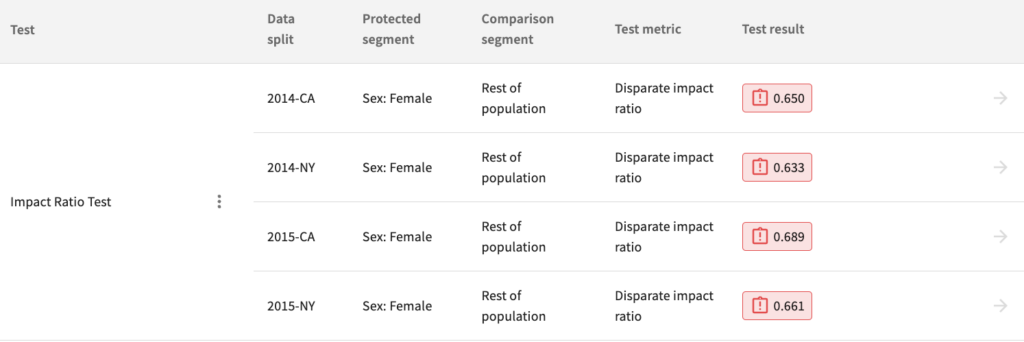
Identify Root Causes: Dataset Disparity
As shown in the model test results, the first version of the test failed the Impact Ratio Test. After further investigations, CA has a better impact ratio than in NY. A potential cause: CA has a smaller difference in observed outcomes, between men and women, a phenomenon referred to as dataset disparity.
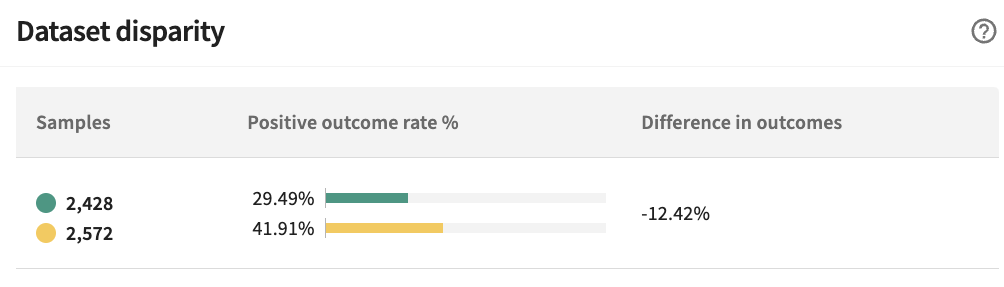
Using the TruEra web app, we can easily view the dataset disparity for both NY and CA. There is a 12.42% difference in outcomes in favor of male (shown in yellow), while females (shown in green) are clearly worse off.
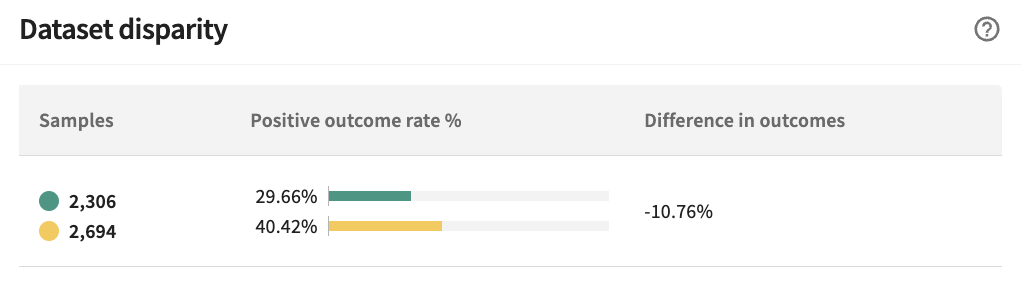
Comparatively, females in California have a -10.76% difference in outcomes.
Debug: Training Data Selection
Retraining our model on California data, which has less disparity in the ground truth data, should result in a more fair model, measured by its impact ratio. After registering the new model, trained on California data, we can then view the updated Impact Ratio test results.
Our second version of the model is substantially more fair, but still fails the impact ratio test based on the four-fifths rule.
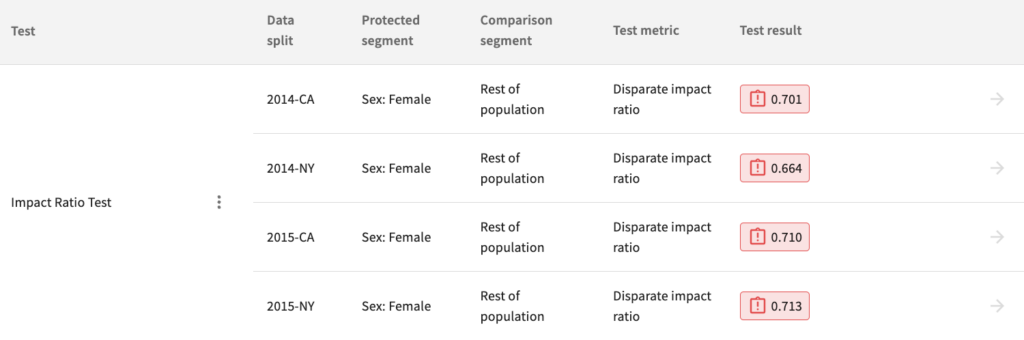
Identify Root Causes: Inclusion of a Protected Variable
Shown on the Fairness page, sex is the highest contributing feature to this disparity. Considering that it is also the feature that segments the protected class, we should remove it. Yet, we will also add it to the extra data so that it is still available for the fairness analysis.
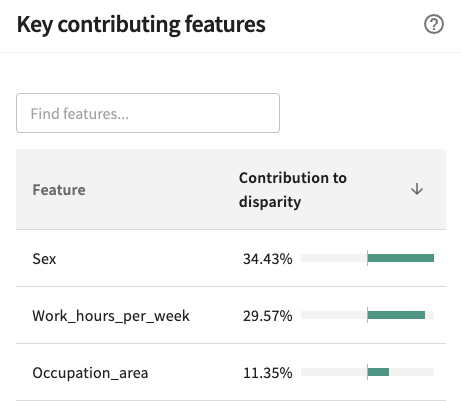
Debug: Feature Removal
First, we’ll need to create a new data collection with sex removed from the feature map.
Then we’ll add the new data splits, with sex moved from the training data to the extra_data.
Our third version of the model now passes the impact ratio test for one of our four data splits, 2015-CA, but we can do better.
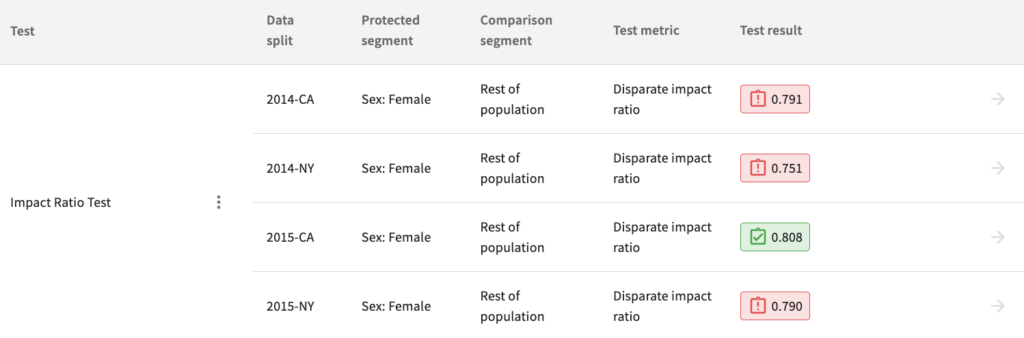
Removal of protected features is often not enough to mitigate the disparate impact of machine learning models because of proxy features – other features that absorb or encode the influence of protected features.
In this case, “work hours per week” and “occupation area” are serving as proxies for “sex”. They are contributing to nearly 70% of the disparate impact observed.
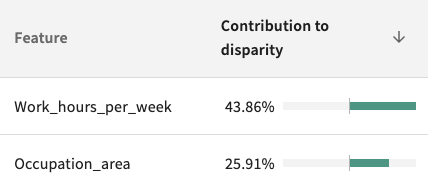
Debug: Rebalance the Training Data
One option to address this issue is to rebalance our training set so that there is no dataset disparity at all.
Let’s do this using the following rebalance_gender() function.
Retraining on the rebalanced data now yields a passing model for all four data splits.
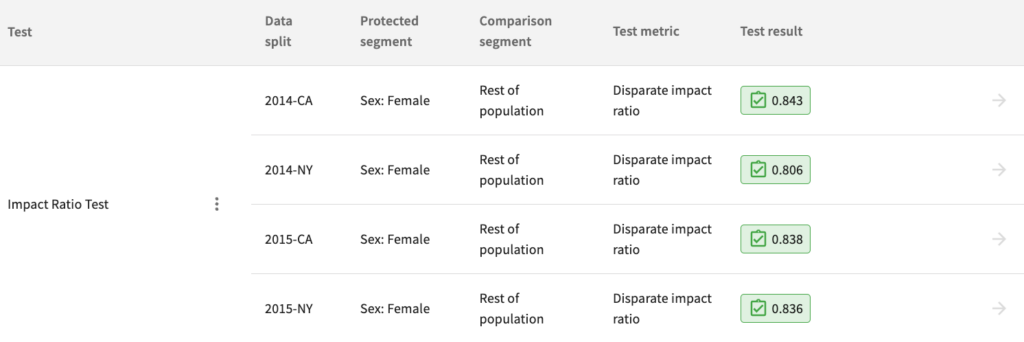
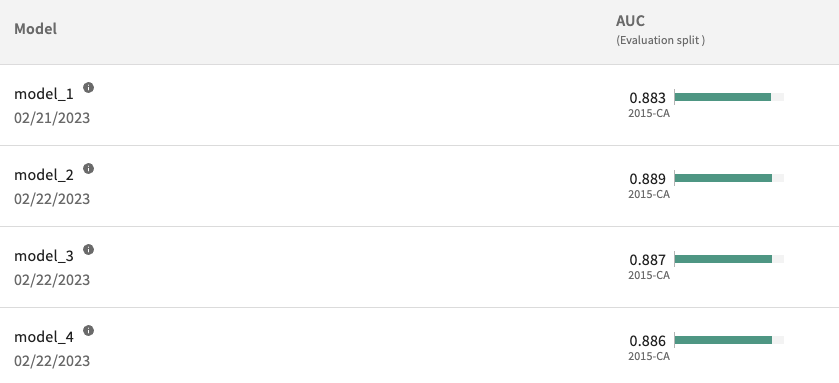
And as shown in the model leaderboard, the model’s fairness and AUC were improved. It is possible to ensure fairness without sacrificing performance.
Ensuring Fairness in ML Models
Ensuring fairness of ML models is a nuanced and complicated challenge, and data scientists need better tools to help them address it. This tutorial used Impact Ratios to evaluate group fairness. After an impact ratio evaluation, we diagnosed root causes of unfair bias including dataset disparity and inclusion of a protected variable. We mitigated these root causes using training data selection, feature removal and rebalancing the training data. Critically, the root causes of bias drove the mitigation and improvement.
Today, ML models that are in production are rarely assessed for their fairness impact. When they are, these assessments are not performed systematically or at scale. This failure may bear a significant cost in terms of reputational risk, poor customer experience and increased consumer distrust. As AI becomes a greater part of our lives, ensuring that models are tested for fairness in development and monitored to ensure ongoing fairness is imperative for businesses and society at large.
Try it yourself!
Get free, instant access to TruEra Diagnostics to de-bias your own ML systems. Sign up at: https://app.truera.net/
Learn More
Want to learn more about evaluating and mitigating bias on your own models? Join our community on Slack.