
Large Language Models (LLMs) have a hallucination problem. Retrieval Augmented Generation (RAG) is an emerging paradigm that augments LLMs with a knowledge base – a source of truth set of docs often stored in a vector database like Pinecone, to mitigate this problem.
To build an effective RAG-style LLM application, it is important to experiment with various configuration choices while setting up the vector database and study their impact on performance metrics.
In this blog post, we explore the downstream impact of some of these configuration choices on response quality, cost & latency with a sample LLM application built with Pinecone as the vector DB. This workflow is also available for you to try in this notebook. The evaluation and experiment tracking is done with the TruLens open source library. TruLens offers an extensible set of feedback functions to evaluate LLM apps and enables developers to easily track their LLM app experiments.
In the RAG paradigm, rather than just passing a user question directly to a language model, the system “retrieves” any documents that could be relevant in answering the question from the knowledge base, and then passes those documents (along with the original question) to the language model to generate the final response. The most popular method for RAG involves chaining together LLMs with vector databases, such as the widely used Pinecone vector DB.
In this process, a numerical vector (an embedding) is calculated for all documents, and those vectors are then stored in a vector database (a database optimized for storing and querying vectors). Incoming queries are then vectorized as well (typically using an LLM to convert the query into an embedding). The query embedding is then matched against the document embeddings in the vector database to retrieve the documents that are most similar to the query.
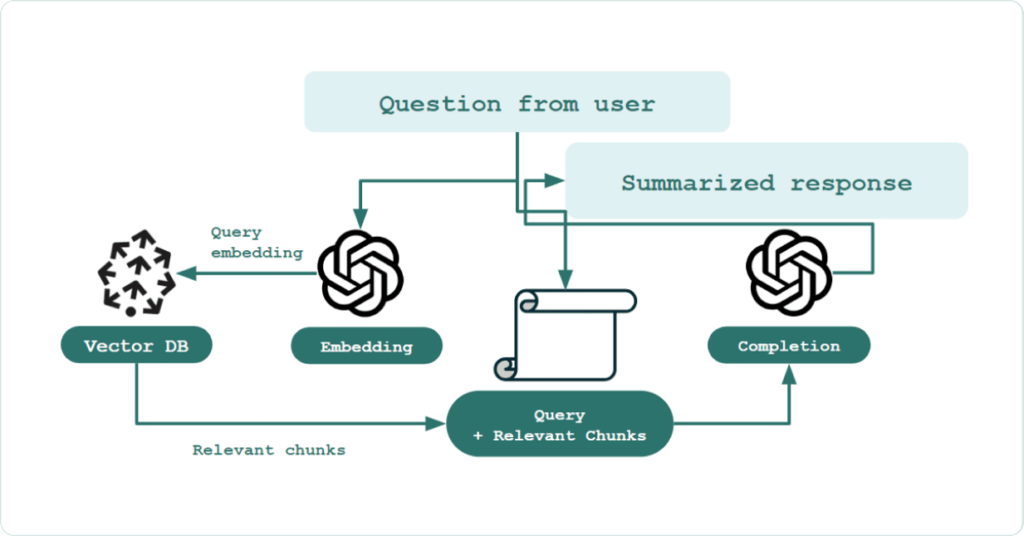
In each component of this application, different configuration choices can be made that can impact downstream performance. Some of these choices include:
Constructing the Vector DB
- Data Selection
- Chunk Size & Chunk Overlap
- Index Distance Metric
- Selection of Embeddings
Retrieval
- Amount of Context Retrieved (top k)
- Query Planning
LLM
- Prompting
- Model choice
- Model Parameters (size, temperature, frequency penalty, model retries, etc.)
These configuration choices are useful to keep in mind when constructing our app. In general, there is no optimal choice for all use cases. Rather, we recommend that you experiment with and evaluate a variety of configurations to find the optimal selection as you are building your application.
We now explore the downstream impact of some of these configuration choices on response quality, cost & latency downstream with a sample LLM application built with Pinecone as the vector DB. The evaluation and experiment tracking is done with the TruLens open source library.
Creating the Index in Pinecone
Here we’ll download a pre-embedding dataset from pinecone-dataset allowing us to skip the embedding and preprocessing steps.
After downloading the data, we can initialize our pinecone environment and create our first index. Here we have our first potentially important choice, by selecting the distance metric used for our index.
Note – since all fields are currently indexed by default, we’ll also pass in an additional empty metadata_config parameter to avoid duplicative (and costly) indexing.
Then we can upsert our documents into the index in batches.
Building the Vector Store
Now that we’ve built our index, we can start using Langchain to initialize our vector store.
In RAG we take the query as a question that is to be answered by a LLM, but the LLM must answer the question based on the information it is seeing being returned from the “vectorstore”.
Initialize our RAG application
To do this we initialize a “RetrievalQA” as our app:
TruLens for Evaluation and Tracking of LLM Experiments
Once we’ve set up our app, we should put together our feedback functions. As a reminder, feedback functions are an extensible method for evaluating LLMs. Here we’ll set up two feedback functions: qs_relevance and qa_relevance. They’re defined as follows:
QS Relevance: query-statement relevance is the average of relevance (0 to 1) for each context chunk returned by the semantic search.
QA Relevance: question-answer relevance is the relevance (again, 0 to 1) of the final answer to the original question.
Our use of selectors here also owes an explanation.
QA Relevance is the simpler of the two. Here we are using .on_input_output() to specify that the feedback function should be applied on both the input and output of the application.
For QS Relevance, we use TruLens selectors to locate the context chunks retrieved by our application. Breaking it down into simple parts:
- Feedback constructor — The line Feedback(openai.qs_relevance) constructs a Feedback object with a feedback implementation.
- Argument specification — The next two lines, on_input and on, specify how the qs_relevance arguments are to be determined from an app record or app definition. The general form of this specification is done using on but several shorthands are provided. on_input states that the first argument to qs_relevance (question) is to be the main input of the app. The on(Select…) line specifies where the statement argument to the implementation comes from. This flexibility allows you to apply a feedback function to any intermediate step of your LLM app.
- Aggregation specification — The last line aggregate(np.mean) specifies how feedback outputs are to be aggregated. This only applies to cases where the argument specification names more than one value for an input.
- The result of these lines is that f_qs_relevance can be now be run on app/records and will automatically select the specified components of those apps/records.
After we’ve set up these feedback functions, we can just wrap our Retrieval QA app with TruLens along with a list of the feedback functions we will use for eval.
After submitting a number of queries to our application, we can track our experiment and evaluations with the TruLens dashboard.
Here is a view of our first experiment:

Experimenting with Distance Metrics
Now that we’ve walked through the process of building our tracked RAG application using cosine as the distance metric, all we have to do for the next two experiments is to rebuild the index with ‘euclidean’ or ‘dotproduct’ as the metric and following the rest of the steps above as is.
Because we are using OpenAI embeddings, which are normalized to length 1, dot product and cosine distance are equivalent – and euclidean will also yield the same ranking. See the OpenAI docs for more information. With the same document ranking, we should not expect a difference in response quality – but computation latency may vary across the metrics. Indeed, OpenAI advises that dot product computation may be a bit faster than cosine. We will be able to confirm this expected latency difference with TruLens.
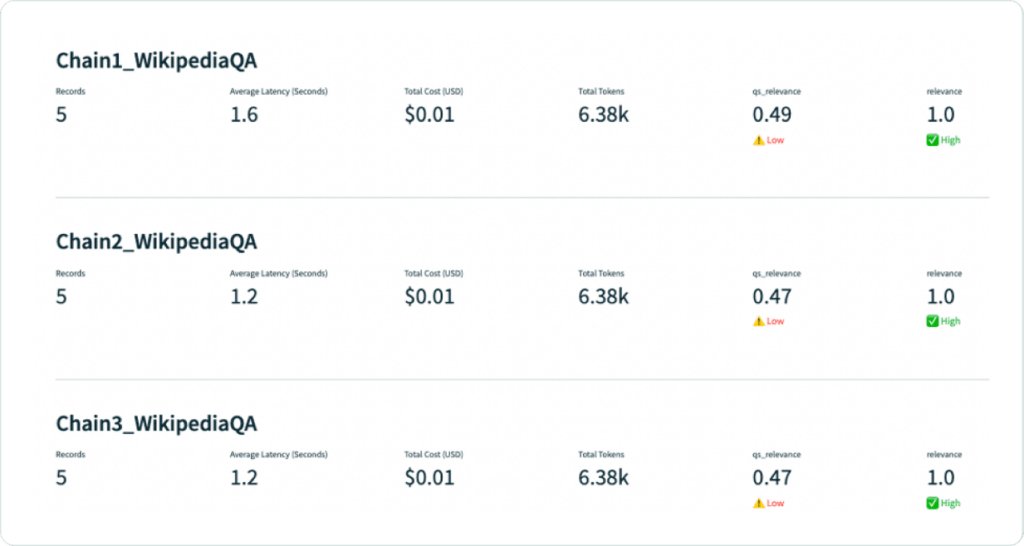
After doing so, we can view our evaluations for all three LLM apps sitting on top of the different indices. All three apps are struggling with query-statement relevance. In other words, the context retrieved is only somewhat relevant to the original query.
We can also see that both the euclidean and dot-product metrics performed at a lower latency than cosine at roughly the same evaluation quality.
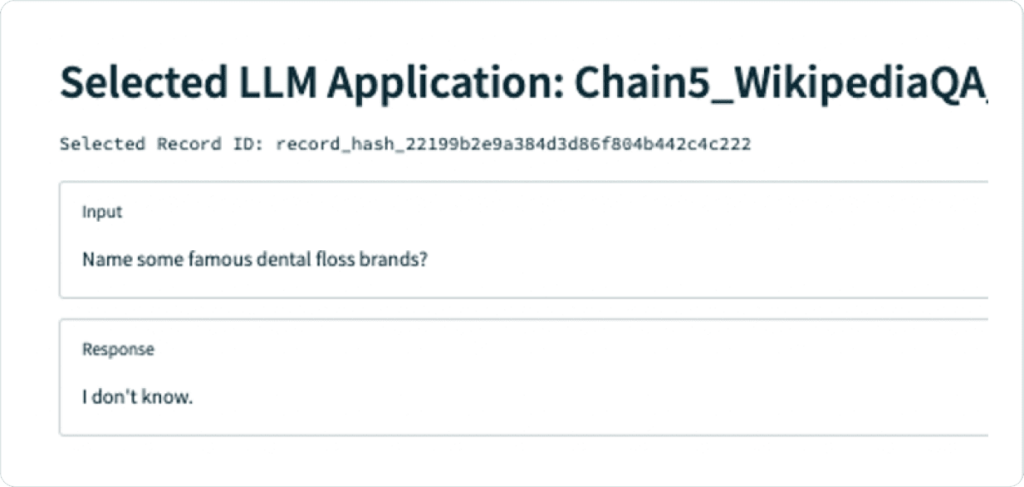
Problem: Hallucination.
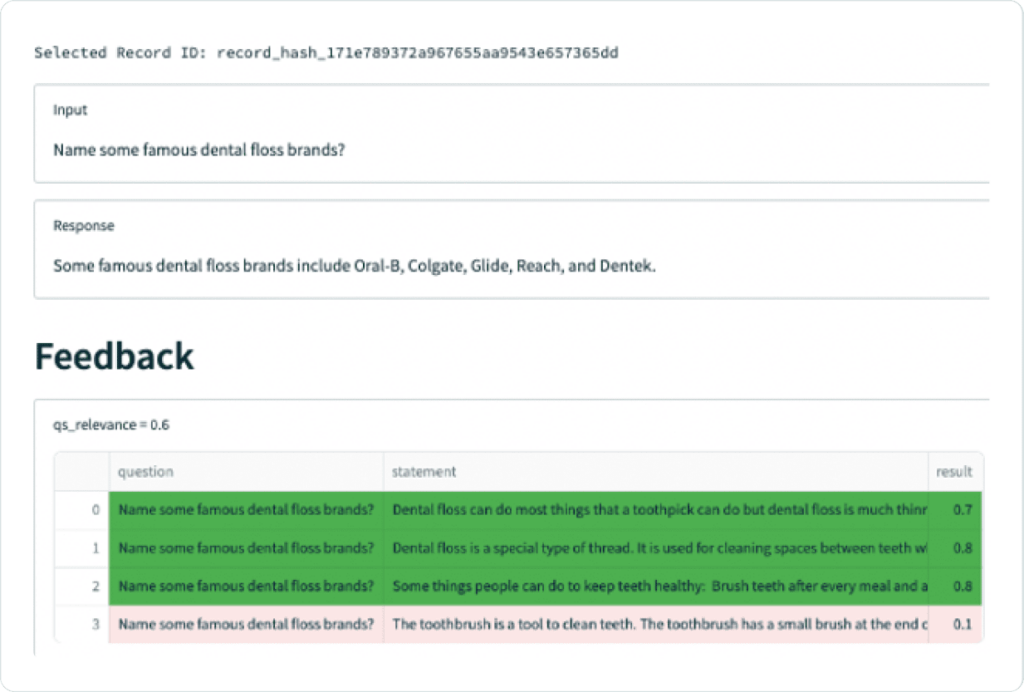
Digging deeper into the Query Statement Relevance, we notice one problem in particular with a question about famous dental floss brands. The app responds correctly, but is not backed up by the context retrieved, which does not mention any specific brands.
Quickly Evaluate App Components with LangChain and TruLens
Using a less powerful model is a common way to reduce hallucination for some applications. We’ll evaluate ada-001 in our next experiment for this purpose.

Changing different components of apps built with frameworks like LangChain is really easy. In this case we just need to call ‘text-ada-001’ from the langchain LLM store. Adding in easy evaluation with TruLens allows us to quickly iterate through different components to find our optimal app configuration.
However this configuration with a less powerful model struggles to return a relevant answer given the context provided. For example, when asked “Which year was Hawaii’s state song written?”, the app retrieves context that contains the correct answer but fails to respond with that answer, instead simply responding with the name of the song.
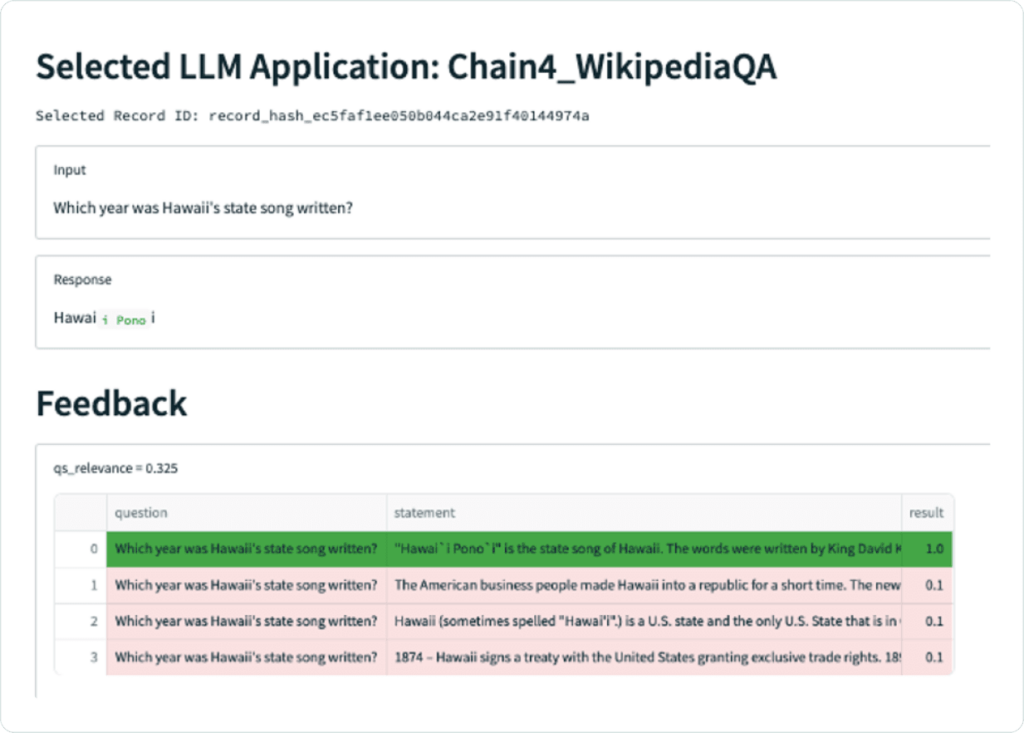
While our relevance function is not doing a great job here in differentiating which context chunks are relevant, we can manually see that only the one (the 4th chunk) mentions the year the song was written. Narrowing our top_k, or the number of context chunks retrieved by the semantic search may help.

We can do so as follows:
Note: The way the top_k is implemented in LangChain’s RetrievalQA is that the documents are still retrieved by our semantic search and only the top_k are passed to the LLM. However TruLens captures all of the context chunks that are being retrieved. In order to calculate an accurate QS Relevance metric that matches what’s being passed to the LLM, we need to only calculate the relevance of the top context chunk retrieved. We can do by slicing the input_documents passed into the TruLens Select function:
Once we’ve done so, our final application has much improved qs_relevance, qa_relevance and low latency!

With that change, our application is successfully retrieving the one piece of context it needs, and successfully forming an answer from that context.
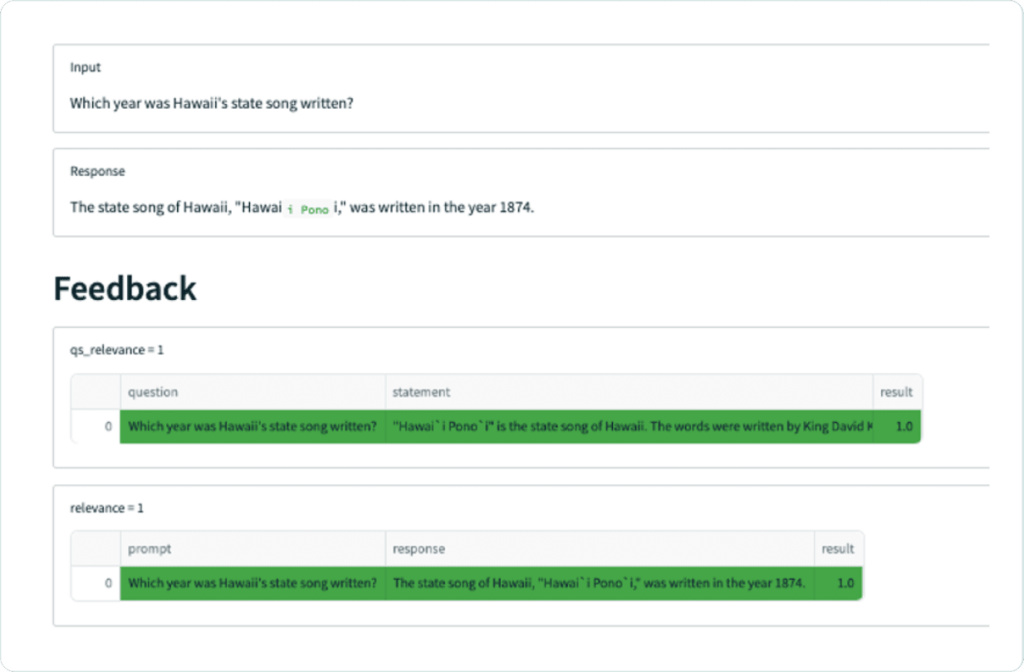
Even better, the application now knows what it doesn’t know:
In conclusion, we note that exploring the downstream impact of some of Pinecone configuration choices on response quality, cost & latency is an important part of the LLM app development process to ensure that we make the choices that lead to the app performing the best. Making this process tool supported requires: (1) programmatic ways of evaluating apps; and (2) tooling for tracking experiments. We showed how this could be supported with the TruLens open source library.
Try this example workflow yourself with this notebook!