
The latest advances in Large Language Models (LLMs), underscored by releases such as OpenAI’s GPT 4, Google’s Gemini and Anthropic’ Claude, have created a lot of excitement among business and tech executives. Yet to date, a tiny percentage of companies have managed to deploy LLMs into production while the vast majority have just built prototypes. Indeed, according to a Truera survey “only approximately 10% of companies have moved more than 25% of their LLM applications into production”. A few barriers are holding organizations such as the ability to generate high quality outputs and meeting data security and governance requirements.
In this context, there is a clear need for tools, practices and techniques to help companies operationalize these models, also known as Large Language Models Operations (LLMOps). This core function allows for the efficient design, deployment and monitoring of LLMs. Similar to Machine Learning Ops (MLOps), LLMOps requires close collaboration between data scientists and DevOps engineers.
In this blog post, we start by introducing a reference architecture for this emerging LLMOps stack. Then, we dive into the observability layer, which sits at the top of the stack. Finally, we contrast Trulens’s approach – Truera LLM Observability tool – with competing solutions.
The LLMOps stack
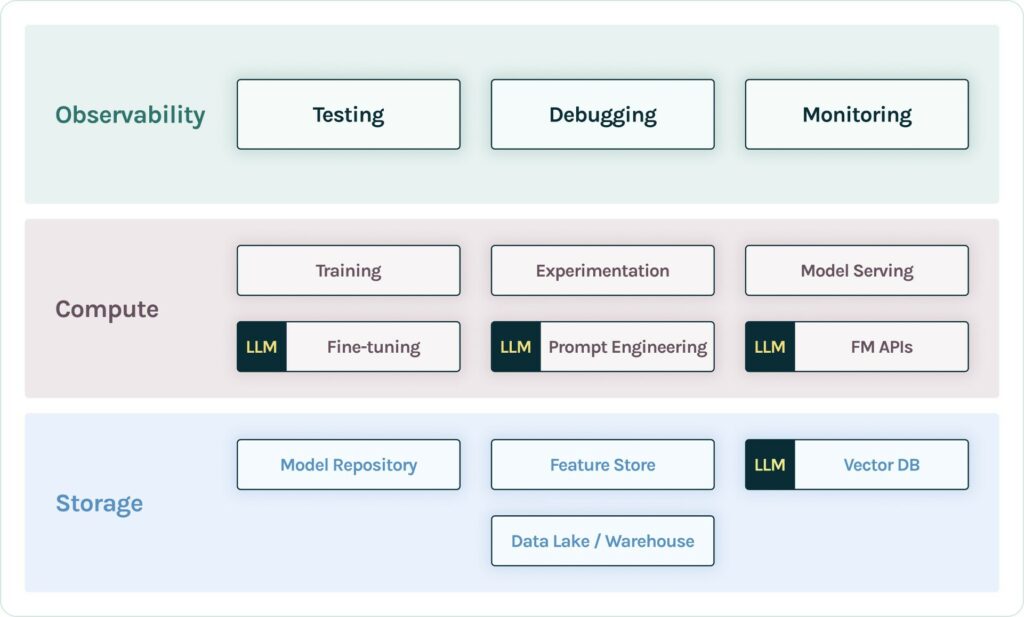
At a high level, the LLM workflow is structured around three layers:
- Storage: This stage involves storing data, features, and models to be retrieved later. They are made available for (re)use in the development of large learning models. In the case of retrieval augmented generation (RAG) models, organization documents are broken into chunks, passed through an embedding model, and then stored in a vector database.
- Compute: This stage includes all steps required to produce a response, 1) query request, 2) prompt construction, 3) prompt retrieval 4) prompt execution, and finally 5) query response. In practice, it requires training a large language model or accessing it through an API, experimenting with prompts and hyperparameters, or additional fine-tuning if deemed necessary. This iterative and highly manual process continues until one gets the app to a satisfactory state.
- Observability: This layer allows one to manage AI quality throughout the LLM-powered app lifecycle, optimizing language models for specific contexts and user expectations. It includes capabilities to evaluate, track, debug, and monitor the performance of large language models at scale.
The observability layer
This recent progress of LLM applications is remarkable in many aspects, but they also create unique risks such as hallucinations, toxicity and bias. LLM observability plays a crucial role in mitigating these risks through systematic tracking, evaluation and monitoring of LLM applications in development and in live use. Most LLM observability solution providers offer similar features. In practice, they enable developers to trace data generated by orchestration frameworks such as LlamaIndex and LangChain, track and visualize inputs/outputs, evaluate LLM apps using evals libraries, compare model versions, and monitor some metrics (e.g. latency, toxicity, faithfulness, context precision, etc).
Such features are useful but insufficient to ensure high-performance performance and reliability across LLM apps lifecycle.
Honest, Harmless and Helpful Evaluations
Trulens’ feedback functions provide a more comprehensive framework for evaluating LLM apps. A feedback function takes as input generated text from an LLM-powered app and some metadata, and returns a score. They can be implemented with simple rule-based systems, discriminatory machine learning models, or LLMs.
Building on the Honest, Harmless and Helpful framework designed by Anthropic for Claude, offers an extensible list of feedback functions:
- Honest: Fundamentally, an LLM app should give accurate information to end users. To this end, it should have access too, retrieve and reliably use the information needed to answer questions it is intended for.
- Harmless: An LLM app should not produce dangerous, offensive or discriminatory outputs. For instance, when asked to aid in a dangerous act (e.g. building a bomb), the AI should politely decline.
- Helpful:An LLM app should be purposely designed to perform a designated task or answer a specific question posed (as long as this isn’t harmful) to the best of its abilities.

This article was co-authored by Jisoo Lee and Lofred Madzou