
The new wave of generative large language models, such as ChatGPT, has the potential to transform entire industries. Their ability to generate human-like text has already revolutionized applications ranging from chatbots to content creation. However, despite their remarkable capabilities, LLMs suffer from various shortcomings, including a tendency to hallucinate, meaning that they often generate responses that are factually incorrect or nonsensical. This is where the concept of retrieval-augmented generation (RAG) comes into play as a potential game-changer. This framework combines the power of retrieval-based models with the creativity of generative models, resulting in a powerful approach to feed contextually relevant data to LLMs. In this article, we will explain how the RAG framework works, and discuss its associated challenges.
LLM-powered chatbot architecture
To explain how retrieval-augmented generation framework works, let’s pick a concrete use case. Assume a data science team is tasked with building a chatbot to support t financial advisors at a bank. The data scientists have various options to develop such an app. They can build an LLM from scratch and then adapt it to their task through fine-tuning on company data but this could get very expensive. Simply using ChatGPT or other popular LLM-powered chatbots would not be much helpful because of their various limitations: context windows limitations, lack of domain-specific knowledge (proprietary data owned by financial institutions), up-to-date information and prohibitive operational costs. In this context, the most sensible approach is to use the RAG framework.
Here is a visualization of the LLM-powered chatbot architecture using retrieval augmented generation:
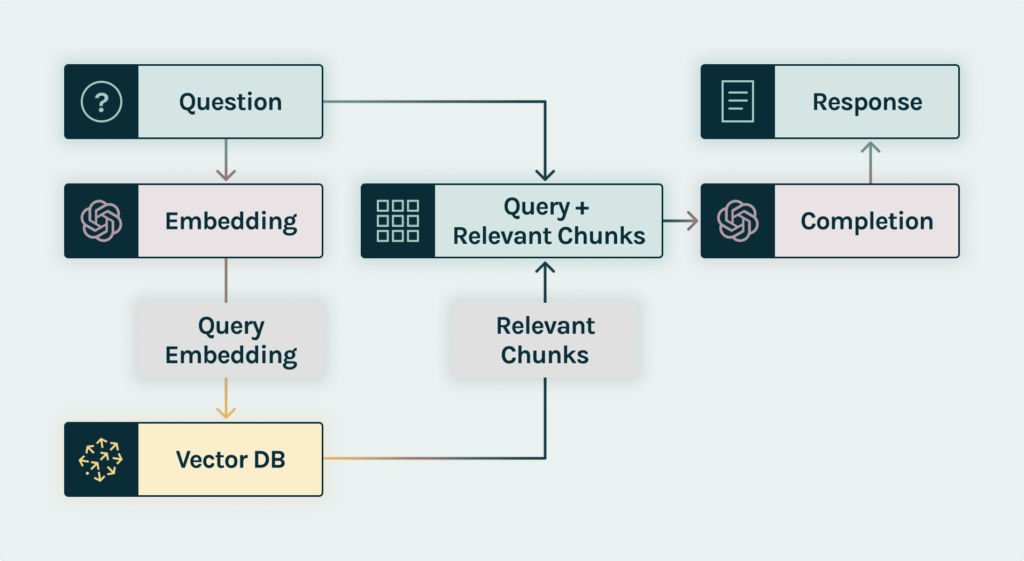
To produce a response, our chatbot would go through the following process:
- Step 1 – data embedding: At this stage, company documents are broken into chunks, passed through an embedding model, then stored in a vector database.
- Step 2 – query request: A financial advisor asks a question about wealth management. For instance, “What are the bull and bear cases for the future performance of Apple stock?”
- Step 3 – prompt construction: using an orchestration framework (e.g., Langchain or LLama-Index), the chatbot requests an embedding API (e.g. ext-embedding-ada-002) to embed the question, and gets back the embedding for the user query.
- Step 4- prompt retrieval: Using the embedding query, it runs a similarity search across a vector database and identifies the top K parameters – most similar pieces of context by cosine similarity (i.e., it measures the similarity between two vectors of an inner product space), and returns chunks of documentation: context 1 and context 2.
- Step 5 – prompt execution: the chatbot takes the user query and the retrieved pieces of context to format it into a single prompt and sends it to the chat completion API (e.g., GPT 3-5) and other self-hosted ones, asking to answer the user query using these pieces of context.
- Step 6 – query response: This answer is shared with the financial advisor.
The key component in figure 1 is the vector database where chunks of documentation converted into vectors using an embedding model are stored (step 1) and then retrieved (step 4) upon request. A vector database is a critical architecture layer ensuring that the chatbot’s response is contextually relevant.
Challenges
Retrieval-augmented generation is a cost-effective and relatively easy-to-implement method to improve the performance of LLM-powered chatbots. Yet, it also comes with its own set of challenges:
- Hallucinations: The RAG framework does a great job at reducing hallucination, but it does completely address this risk. Indeed, if a vector database connected to the LLM does not include contextually relevant data, one would still get its most probable guess, but it might just be a hallucination.
- Fine-tuning complexity: Fine-tuning a generative model in a retrieval-augmented setup requires careful balancing. Fine-tuning RAG models often requires a specialized dataset that combines retrieval and generation tasks. Annotating such data can be labor-intensive and expensive, as it involves not only providing appropriate retrieval passages but also generating coherent responses. Finally, overfitting to the retrieval documents or losing generative fluency are serious risks.
- Data quality and bias: Retrieval models rely heavily on the quality and diversity of the data they retrieve. If data in the vector database is biased, then produced responses are likely to be biased too. That is the reason why it is essential to ensure that the retrieved data is not unfairly biased.
- Lack of evaluation metrics: Traditional evaluation metrics for natural language generation, such as BLEU or ROUGE, may not fully capture the effectiveness of retrieval-augmented generation systems. Developing appropriate evaluation methods that consider both retrieval and generation aspects is an ongoing challenge.
Conclusion
The Retrieval-Augmented Generation (RAG) framework has emerged as a powerful approach to improve the performance of LLM-powered apps by feeding LLMs with contextually relevant information. This eliminates the need to constantly retrain and update them while mitigating the risk of hallucination. Yet RAG is still imperfect and raises various challenges. At TruEra, we are working on improving Retrieval-augmented Language Models by adding an observability layer that enables ML teams to evaluate, track and monitor LLM-powered apps, leading to higher quality and trustworthiness.