
For Consumer-Oriented Retail, Brand, Manufacturing and Tech Businesses
TruEra recently conducted an executive private seminar with 40+ senior AI leaders to share their lessons learned regarding best practices in developing and deploying LLM applications. The event featured an expert panel including:
- Ping Wu, CEO at Cresta
- Erwan Menard, Director of Cloud AI Product Management, Google Cloud
- Xun Wang, CTO at BloomReach
- Anupam Datta, President and Chief Scientist at TruEra
Key Takeaways from the Expert AI Panel
The panel discussion had the following key take-aways:
- Companies are moving up the maturity curve. Companies are moving their LLM app focus from demos and experimentation to achieving business success in production
- Quality and security are top pain points. Generating relevant, high quality output and meeting data security and governance requirements are the top two pain points in achieving LLM success
- There are best practices for better LLM app quality that can be put in place today. Achieving relevant, high quality output requires implementing best practices for defining quality, new ways to cost efficiently evaluate and track LLM app quality throughout the life cycle, and good UX design
- Thoughtful design and guardrails are key to governance. Achieving data security and governance requires thoughtful model selection and app architecture design and implementing application appropriate guardrails.
- We are just at the beginning of increasing innovation and effectiveness. We are likely to see multiple models and multiple architectural approaches being successful and continued improvements in cost, latency, and quality
Moving from Demos to Real Business Success
The panel agreed that 2023 was the year for building prototypes of LLM apps – but that relatively few actually made it into production. TruEra’s past surveys have shown that only approximately 10% of companies have moved more than 25% of their LLM applications into production. More than 75% of companies have not moved any LLM apps into production at all.
Figure 1: Share of LLM Applications that have moved to production
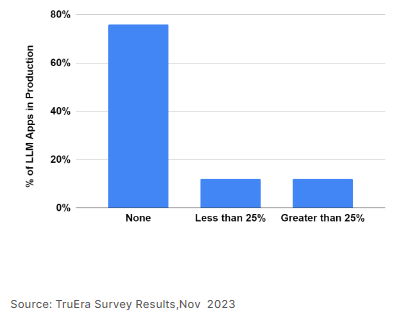
Now, however, as Erwan Menard, Director, Cloud AI at Google, pointed out in the panel, companies are under pressure to move more LLM applications into production and most importantly to achieve business success with them. Whereas 2023 was the year for investigation and prototyping, 2024 will be the year for achieving business impact with LLM apps. Some of these applications will achieve business success, but it will also be true that some may not succeed, especially if companies do not invest in best practices around the development and deployment of LLM apps. As with any hype cycle, the panel recognized that there may be some disillusionment amongst the success.
Pain Points in Achieving LLM Application Business Success
During the panel, we conducted a poll to understand the audience’s top 3 pain points in building and deploying successful LLM apps. The clear, top two pain points in achieving LLM success were:
- Generating high quality output
- Meeting data security and governance requirements
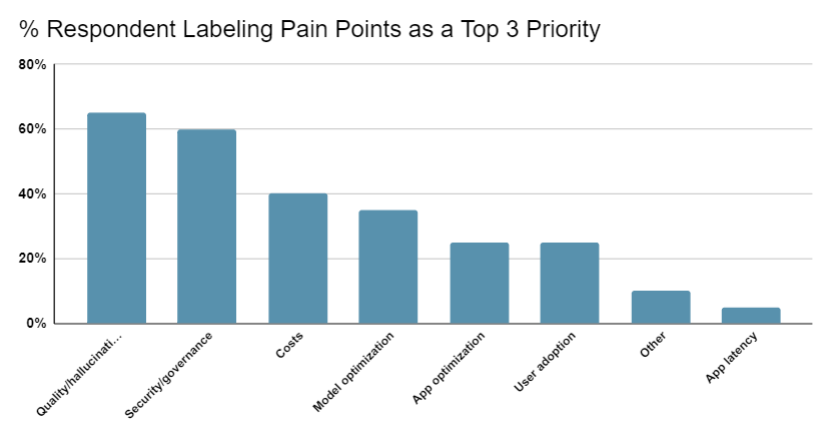
Respondents were also concerned about costs; LLM model selection/optimization (e.g., fine tuning); user adoption; and application optimization (e.g., RAG/vectorDB optimization, prompt engineering, etc.).
Best Practices for Addressing LLM App Quality, Relevance, and Hallucinations
Panelists and participants in our breakout discussions agreed that the top challenge was ensuring that LLM applications generated high quality, relevant output. For some applications, such as the generation of artistic content, LLM hallucinations are a beneficial feature. But for many business applications, such as summarization and Q&A applications, hallucinations are bugs.
The best practices for addressing these challenges discussed by the panel and within breakout sessions include:
- Define quality or relevance for your LLM application. Xun Wang, CTO of BloomReach, identified this as a key challenge that can become a significant unknown in development if not defined. The definition of quality will vary for different applications and for different use cases and verticals. For financial or healthcare applications, for example, high quality, relevant results are a must-have. Thus creating vertical specific benchmarks are useful for both provider and customer to align on what quality means for a use case.. In some applications, for example, there may be a value to leveraging some of the general knowledge of the LLMs versus only using a company identified knowledge store, while finding other ways to mitigate hallucinations using system 2 methods like Chain of Thought.
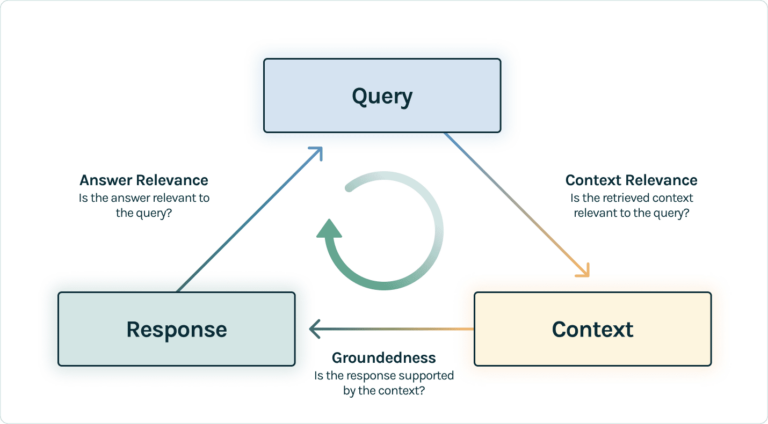
- Develop new ways of evaluating LLM apps. Anupam Datta, Co-Founder & Chief Scientist of TruEra, pointed out that generative apps will require new ways of evaluating quality or accuracy vs prior apps, such as traditional classification/regression ML apps that use accuracy measures and prior language apps, such as search. Many measures of quality from language applications such as precision, recall, ranking do apply, but new measures such as groundedness (i.e. ensuring that the final response is grounded in the source documents) are necessary given the new dynamics that arise from hallucinations. TruEra has developed best practice methodologies for LLM evaluation such as the RAG triad (see “How to Prevent LLMs from Hallucinating?“)
- Track experiments during development. Anupam discussed how evaluations during development can be critical for running application design experiments and understanding the performance of different designs. For example, evaluation experiments that measure quality measures such as relevance and groundedness, cost and latency can be used to select the best LLM model for an application and to optimize prompts and vector database configurations.
- Monitor quality measures during production. Xun mentioned that it is also critical to continue to track and evaluate quality in production. There is no way to identify all of the potential quality issues during development. In production, app developers will see new prompts that they have not anticipated – just like Google search sees >15% new queries each day. The content in an application’s knowledge store will change. The behavior of the LLMs will also change over time as they are updated. Monitoring quality will be critical to maintain application quality and consistently achieve business success. Anpuam pointed out that developers will need to consider the cost and latency of app evaluations themselves. For example, using other LLMs to evaluate an LLM app might work during development but these will not cost-effectively scale since the cost of monitoring could then become 10X the cost of running the app.
- Use UX to create a quality application experience. Ping Wu pointed out that Cresta improves the quality of applications through a number of UX features, including providing references for a response, soliciting and responding to human feedback, incorporating human feedback, and integrating generative content with heuristics and playbooks.
Best Practices for Addressing LLM App Data Security and Governance
The other major set of problems discussed included data security and governance. These problems have increased in priority as companies start to define the data security, safety, legal, and governance requirements they need to meet to move applications into production.
The best practices for addressing these challenges discussed by panelist and within breakout sessions include
- Utilizing different types of architectures. Erwan pointed out that there are many flavors of RAG architectures depending on the strength of the governance requirements. For instance, some RAG architectures may use keyword search for retrieval while others might use highly optimized vector databases
- Utilizing different models. Ping discussed how Cresta gains greater control, efficiency, and explainability by using medium size language models for certain use cases in addition to LLMs.
- Implementing guardrails. Governance can be addressed by implementing guardrails that detect and/or prevent governance issues such as truthfulness. Anupam pointed out that these guardrails are similar to evaluations but that, to be used as guardrails, they need to be low latency to be used in real-time. This requires specialized models like those that TruEra has developed as LLM based evals are both higher latency and higher cost.
- Use governance services. Erwan pointed out that new governance tools and services are being developed. For example, Google offers copyright infringement protection.
An exciting multiple model future for GenAI and LLM Apps
The panel expressed universal excitement for the future of generative AI. While there might be some examples of failures, they believed that LLM applications will achieve significant business impact. In addition, the costs and performance of LLMs are bound to improve increasing ROI and growing the use of LLM applications. In addition, the group envisioned that multiple models will be used for different applications. Xun believed that open source LLMs will see increasing adoption. Evaluations during development and production will significantly increase LLM adoption. New technology solutions for evaluation, such as those being built by TruEra, will be needed to enable broad adoption of LLM applications. The adoption of generative AI is only just beginning.
Interested in seeing the panelists in action? Check out a recording of “Best Practices in Developing and Deploying LLM Applications,” which is now publicly available.
For more information on LLM evaluation best practices, go to:
- New, hands-on course on Building and Evaluating Advanced RAG Apps featuring Anupam Datta, Jerry Liu, and Andrew Ng.
- Prof. Andrew Ng post on the free RAG course.
- Blog – “Build and Evaluate LLM Apps with LlamaIndex and TruLens”
- Blog – “Evaluating Pinecone Configuration Choices for Retrieval Augmented Generation (RAG) with TruLens“




{kind=link}