
Machine learning explainability can do much more than just explain model outcomes. It can improve the quality and trustworthiness of ML models throughout the lifecycle, enabling adoption of ML at scale.
Explainability: A Means to Model Quality and Trustworthiness
It’s understandable for people to be concerned or hesitant about new processes that are mysterious, especially if those processes have a significant impact on their lives, such as determining if they can get credit, get a job, or get admitted to their desired school. The black box nature of AI runs directly into this concern. The need for greater transparency into the way in which models make their predictions is clear, and has led to a flourishing in academic and commercial efforts around ML explainability.
However, viewing explainability in isolation misses the bigger picture. First, explainability is rarely an end in itself. Instead, explainability can serve as a greater mechanism to test, debug, validate, and monitor models. Transparency into a model’s ways of making predictions is useful, but the broader end goal must be to achieve high model quality and trustworthiness. Model quality in this case is much more than the accuracy of the results. Validating a model’s conceptual soundness, probing it for signs of unfair bias, and inspecting its stability on new data are some of the model quality analyses that can be enabled by robust and accurate explanations.
Explainability across the Model Lifecycle
Further, explainability should be thought of as an effort that impacts and is involved with every step throughout the model lifecycle. A key driver of the surprisingly long time it takes to deploy ML models in production is the disconnect between model development and the subsequent steps of model review/ validation and buy-in from businesses. Embedding explainability early into the model lifecycle can help data scientists continuously debug and improve their models well before formal review or validation. Also, many problems with ML models start after they have been deployed, when shifting data or data relationships start impacting results. To maintain ongoing trust in ML models, it is critical to also have the ability to explain and debug ML models after they go live.
The following figure illustrates the limited extent to which explainability is used today, and how it can be better used across the ML lifecycle to drive ongoing model quality and trustworthiness.
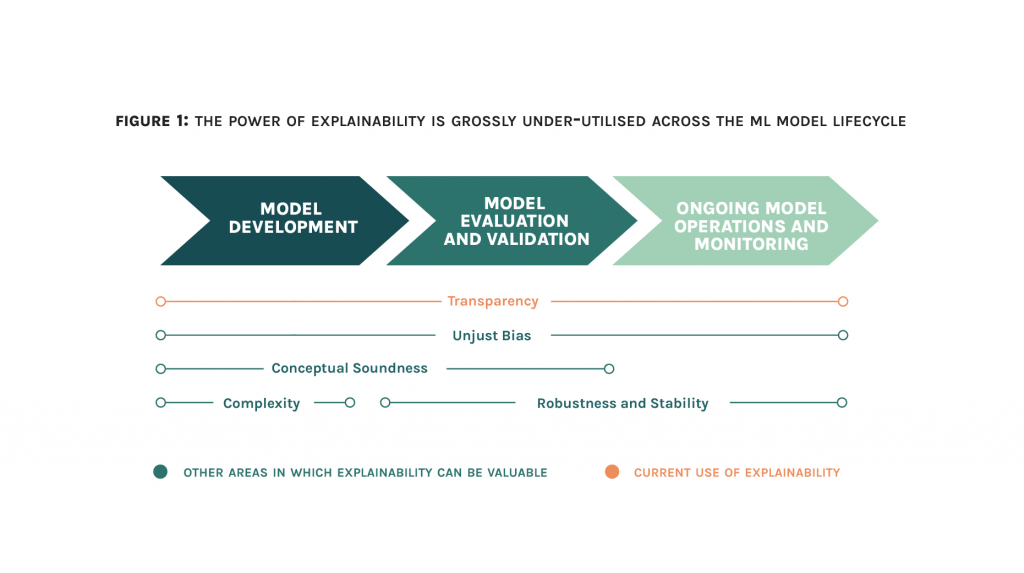
Deep dive: from Explainability to Model Quality
So how does a good explainability framework underpin broader model quality assessments? In this section, we detail just a few of the key model quality checks that can be accomplished when there are robust explanations, and how they can be used throughout the model lifecycle to enhance trustworthiness.
Transparency
Used for: Development, Validation, Monitoring
The most straightforward application of explainability is to gain increased transparency in a model. Once you are convinced that your model is reasonably accurate, it’s important to ensure it is making its decision for the right reasons. There are three buckets of achieving transparency via explanations.
For example, using a lending use case:
- Point-level decisions: Why was Jane denied a loan? Why was Jane denied a loan compared to other women?
Local explanations are necessary to explain individual decisions, and can enable businesses to suggest actions that a user could take to change a decision (e.g. acquire a loan). These explanations need to be flexible, and identify why a decision was made for various comparison groups and query types. Point-level decisions are especially critical to provide reason codes to end-users.
- Global/aggregate decisions: What are the overall drivers of my model?
Beyond individual decisions, a robust explanation framework must also identify the overall causal drivers of the model. Global feature importances can uncover the high-level reasons for model performance, and pinpoint the information that the model considers meaningful. This is a great sanity check for developers to see whether models match human intuition.
- Sensitivity: If I vary income, how does this affect someone’s chances of getting a loan?
ML models use variations in features as the basis of their decision-making. Tools such as influence sensitivity, partial dependence and accumulated local effects plots can help visualize this.
Conceptual Soundness
Used for: Development, Validation
ML models can encode complex and non-linear relationships, necessitating a deeper dive on feature behavior. How does a model rely on a feature as the feature value changes? Do we expect linearity and/or monotonicity, or a different behavior pattern altogether? Sensitivity analyses (one of the three key components of a robust explainability framework) provide a built-in model quality check for conceptual soundness. Influence sensitivity plots can give developers and model validators a chance to confirm that feature-level behavior matches intuition.
Data scientists work with hundreds or thousands of inputs to a model, creating a curse of dimensionality. Prioritizing which behaviors to examine closely can be critical. Feature focusing capabilities provide a way to automatically flag features which are likely to contain concerning behavior.
In the following example, the model developer or validator was able to use the influence sensitivity plot to identify potential issues with the Debt to Income Ratio (DTI) feature, which appears to be lowering credit risk as it goes up.
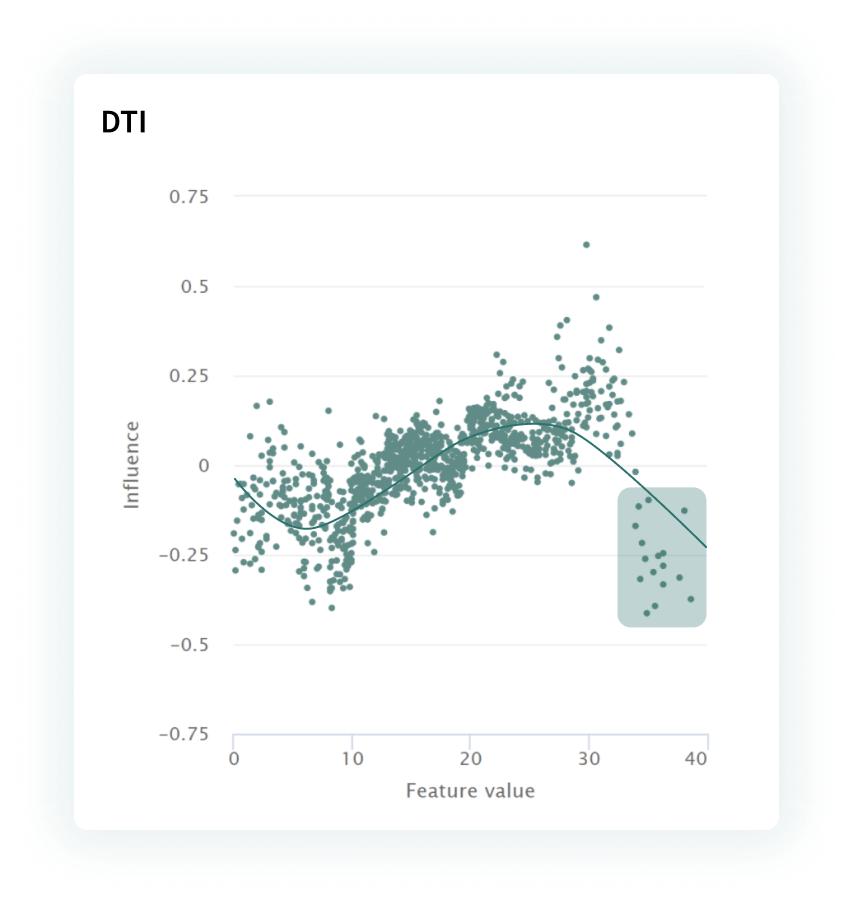
FIGURE 2 | The influence sensitivity plot for this model shows erroneous behavior for high feature values, where high debt-to-income ratios should be driving up model risk rather than down.
Robustness and Stability
Used for: Validation, Monitoring
ML models are prone to overfitting, such that they do not generalize beyond their training data. However, use of an explainability solution ensures that model validators can get the guidance that they need to perform targeted model stability checks. In particular, measuring how feature importances shift across splits can indicate whether the drivers of model decisions are changing. This can also elucidate whether a degradation in performance is due to changing data (distribution shift) versus changing relationships between variables (concept drift).
In the following example, explanations enabled the data scientist to identify that the main contributor to differences in a credit model’s predictions before and after COVID-19 were change in income (annual_inc) and loan purpose (purpose).
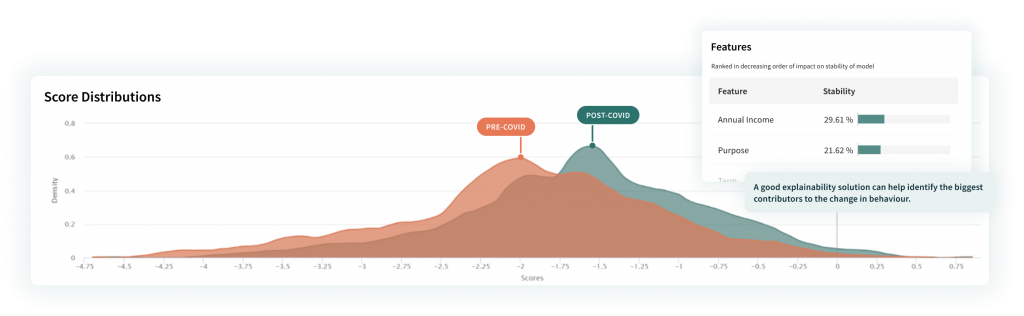
FIGURE 3 | Using explainability to identify root causes of changes in model behavior. Here, by analyzing how feature importances have shifted from pre-COVID-19 data to post-COVID-19, the features that are driving model instability are immediately surfaced.
Unjust bias and fairness
Used for: Development, Validation
AI/ML models replicate relationships from the data on which they are trained, and can latch on easily to biases that are prevalent in a dataset. A more systematic approach is needed to detect unjust bias, particularly due to unintended use of proxies for protected data elements (e.g., using continuous employment as a proxy for gender). This is why explanations with flexible comparison groups are so critical– by examining explanations by varying comparison groups by protected features, bias and fairness for population subgroups can be systematically evaluated.
In the following figure, the explainability solution has enabled the data scientist to identify that the main contributor to the differences between male and female applicants was their marital status. A subsequent investigation into the underlying data highlighted that this was due to a biased training dataset, in which men were four times more likely to be married compared to their female counterparts. Clearly, this was not reflective of the real world, and interventions were made to correct this bias.
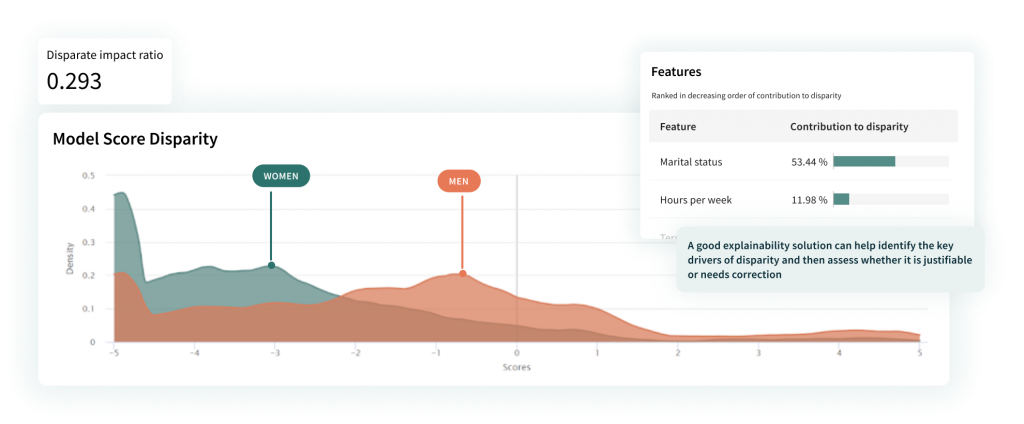
FIGURE 4 | Using explainability to identify root causes of disparity between men and women
Complexity
Used for: Development
ML models are notoriously overparameterized or underspecified. If an AI/ML model can be simplified without significant performance hits, this can relieve a burden on developers and validators. Explanations can actually simplify the model itself by identifying redundant features, the most important features that are primary drivers of model results, and critical model pathways. In addition, “bugs” in faithful explanations can be evidence of underlying model quality issues; on well-behaved and appropriately complex models, these anomalies should not exist.
***
It is time to rethink the role of explainability in machine learning. Beyond its centrality to the transparency of models, it can also serve as the backbone of broader assessments of model quality, such as those around robustness, fairness, conceptual soundness, and stability. This can help build trust in machine learning models and enable adoption of machine learning at scale.
Not all explanation frameworks are made equal. Interested in learning more?
Read the previous blog post: Machine learning models require the right explanation framework. And it’s easy to get wrong
Authors
Shameek Kundu, Head of Finance and Chief Strategy Officer
Anupam Datta, Co-Founder, President, and Chief Scientist
Divya Gopinath, Research Engineer