
Today, we are excited to announce TruLens for LLM Applications – the first open source software to evaluate and track LLM experiments. You can download it now from PyPi – TruLens for LLMs – and integrate it into your app dev process with just a few lines of code. You can leverage TruLens to rapidly iterate on your LLM apps, guard against risks from LLMs, and make tradeoffs among performance, cost, and other factors.
Developer activity with LLMs has hit an inflection point
The release of ChatGPT by OpenAI six months ago and its rapid acquisition of users (100 million in just 2 months!) has made obvious the tremendous opportunity and surrounding risks of Large Language Models (LLMs) to companies, governments, and the public at large. In addition to OpenAI’s GPT series, a strong set of LLMs are also available for use from other organizations, including Anthropic’s Claude, co:here, Google’s PaLM 2, Meta’s LLaMA, and HuggingFace/Big Science’s BLOOM.
The rise of LLMs has also catalyzed tremendous developer activity, with tens of thousands of developers building LLM applications, including question-answering, chatbots, document summarization, search, generative writing tasks such as marketing copy, and more. This activity has been facilitated by:
(1) easy-to-use APIs (e.g. from OpenAI) via which LLMs can be called without the need for hard-to-build MLOPs pipelines to collect and clean data, train, and deploy models; and
(2) developer frameworks, such as LangChain and LlamaIndex for augmenting LLMs with additional resources (e.g. external data stored in vector databases like Pinecone and Chroma).
Experimentation is key to building powerful LLM apps – but it’s too hard to do today
The workflow for building LLM applications involves significant experimentation. Consider a developer building a Question Answering application. After developing the first version of the app, she may test it by supplying a series of questions and manually reviewing the answers. If a question is incorrectly answered, she may make adjustments – changing prompts or hyperparameters of the retrieval system or fine-tuning LLMs – and then re-testing the revised app. This iterative, highly manual process continues until she gets the app to a satisfactory state.
This process is time consuming. Until now, there were no useful tools to measure app performance and quality metrics. It was also difficult to track how metrics are improving (or not) after each iteration.
TruLens helps you refine LLM experiments quickly with programmatic feedback
TruLens fills this gap in the LLMOps tech stack by supporting LLM developers with tooling to evaluate and track LLM experiments. TruLens leverages a new framework that we’re calling feedback functions to programmatically evaluate the quality of inputs, outputs, and intermediate results from LLM applications, thus scaling up the human review steps. While TruLens comes with an out-of-the-box set of feedback functions, we invite developers to add functions tailored to their application needs to the library. Out-of-the-box feedback functions today include:
- Truthfulness
- Question answering relevance
- Harmful or toxic language
- User sentiment
- Language mismatch
- Response verbosity
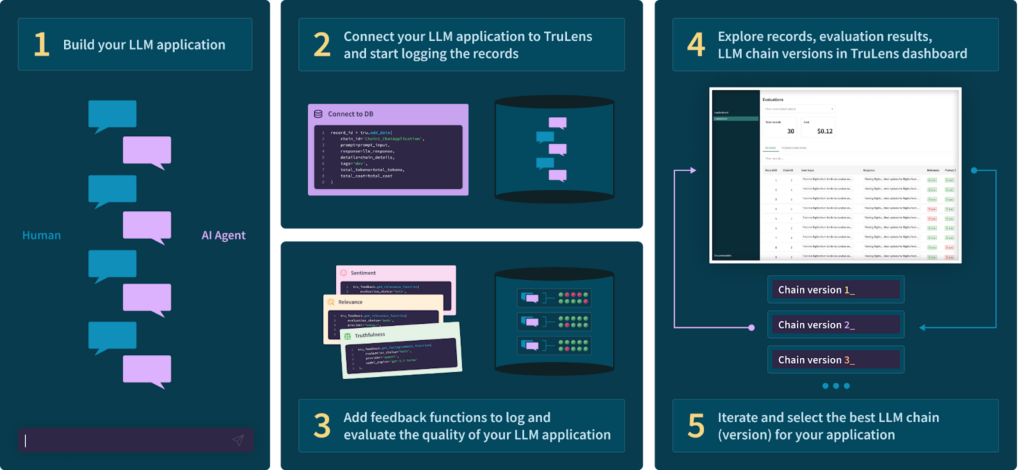
Figure 1: Workflow for faster LLM app development using TruLens
How to accelerate and improve LLM app development with TruLens
Developers can use TruLens as they are building their LLM applications in Python by following these steps, illustrated with a running example of a Question-Answering (QA) application. You can also go directly to the TruLens for LLMs Quick Start page to get started with using TruLens right away.
1. Build your LLM app
When you are using TruLens, you would build the first version of your LLM app following your standard workflow.
We built a Question Answering app named “TruBot” following the widely used paradigm of retrieval-augmented LLMs. This approach grounds the app’s responses in a source of truth or knowledge base – TruEra’s website in this case. It involved chaining together the OpenAI LLM with the Pinecone vector database in the LangChain framework (see Appendix A for more details). The code for the key steps for implementing this app are shown in Figure 2.
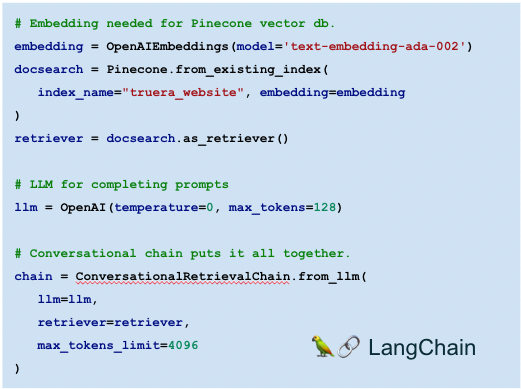
Figure 2: Example of a chained Question Answering LLM app, TruBot
2. Connect your LLM app to TruLens and log inputs and responses
The next step is to instrument the app with TruLens to log inputs and responses from the chain. Note that this step is very easy – it involves wrapping the previously created chain, running it, and logging the interaction with just 3 lines of code.

Figure 3: How to connect a Question Answering LLM app to TruLens
3. Use feedback functions to evaluate and log the quality of LLM app results
The third step is to run feedback functions on the prompt and responses from the app and to log the evaluation results. Note that as a developer you only need to add a few lines of code to start using feedback functions in your apps (see Figure 4(a)). You can also easily add functions tailored to the needs of your application.
Our goal with feedback functions is to programmatically check the app for quality metrics.
- The first feedback function checks for language match between the prompt and the response. It’s a useful check since a natural user expectation is that the response is in the same language as the prompt. It is implemented with a call to a HuggingFace API that programmatically checks for language match.
- The next feedback function checks how relevant the answer is to the question by using an Open AI LLM that is prompted to produce a relevance score.
- Finally, the third feedback function checks how relevant individual chunks retrieved from the vector database are to the question, again using an OpenAI LLM in a similar manner. This is useful because the retrieval step from a vector database may produce chunks that are not relevant to the question and the quality of the final response would be better if these chunks are filtered out before producing the final response.

Figure 4(a): Example of feedback functions to check for language match and relevance
Note that feedback functions are a general abstraction. They can be implemented in a number of ways, including but not limited to using modern LLMs, previous generation of BERT-style models, as well as with simpler rule based systems in some cases. We refer the interested reader to our article on feedback functions for more detail.
- You can also configure TruChain to use automatic feedback computation and logging as shown in Figure 4(b). This combines steps 2 and 3 into one line of code.

Figure 4(b): Configuring TruChain to use automatic feedback computation and logging of a feedback function for LLMs
Note that feedback functions are a general abstraction. They can be implemented in a number of ways. One practical consideration in using feedback functions is cost, in particular, when they are implemented by calling LLMs over APIs. We note that there are a number of free implementations that are available from OpenAI and Hugging Face that provide a useful starting point. Over time, we also expect that the library of feedback functions will incorporate other low cost mechanisms, including but not limited to previous generation of BERT-style foundation models, as well as with simpler rule based systems. We refer the interested reader to our article on feedback functions for more detail.
4. Explore in dashboard
After running the feedback functions on a set of records (interactions), you can
- see the aggregate results of the evaluation on a leaderboard (see Figure 5);
- then drill down into an app version (or chain) and examine how it is performing on individual records (see Figure 6).
These steps can help you understand the quality of an app version and its failure modes.
For example, in Figure 5, we see that this app version (Chain 0) is not doing well on the language match score from our feedback function. Drilling down in Figure 6, we discover that when questions are asked in German it responds in English instead of German – that’s the failure mode.
The app is doing well on overall relevance of responses to questions. However, it is performing poorly on the qs_relevance feedback function. Recall that this function checks how relevant individual chunks retrieved from the vector database are to the question. See Appendix B for an explanation of this failure mode.
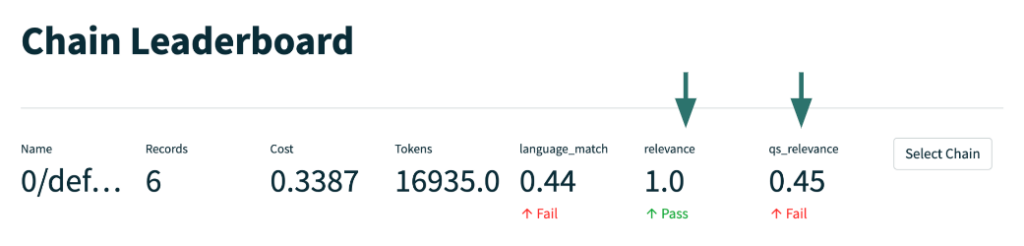
Figure 5: Example of a feedback function chain leaderboard for evaluating LLM apps
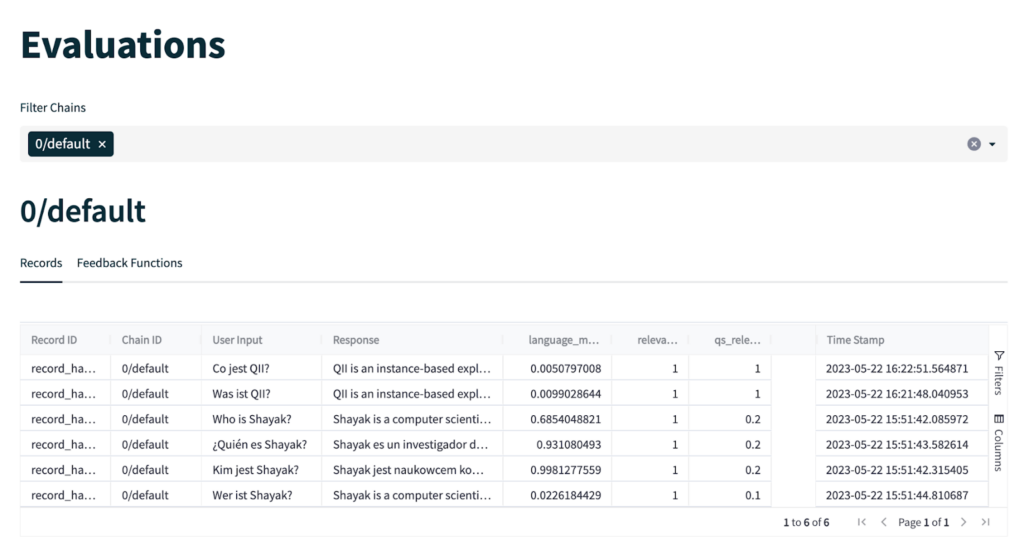
Figure 6: The Evaluations table provides a drill down of the evaluation at the record level. Note that on the language match test, this chain does not perform well when asked questions in German whereas it correctly responds in Spanish when asked a question in Spanish.
5. Iterate to get to the best chain
Armed with an understanding of the failure modes of the first chain, you then proceed to iterate on your app.
To address the language match failure mode, you adjust your prompt as shown in Figure 7. Running the evaluation again on the new version of the app (Chain 1), you see an improvement on the leaderboard – the feedback function score for language_match went from 0.44 to 0.93 (see Figure 8).

Figure 7: Adjusted prompt to address language match failure mode that is surfaced by a feedback function. Note the explicit instruction to answer in the same language as the question.
To address the irrelevant chunks failure mode, you filter the contexts using the qs_relevance feedback function as shown in Figure 8. Running the evaluation again on the new version of the app (Chain 3), you see an improvement on the leaderboard – the feedback function score for qs_relevance increases significantly (see Figure 8). Chain 4 incorporates both the language prompt adjustment and the context filtering step.
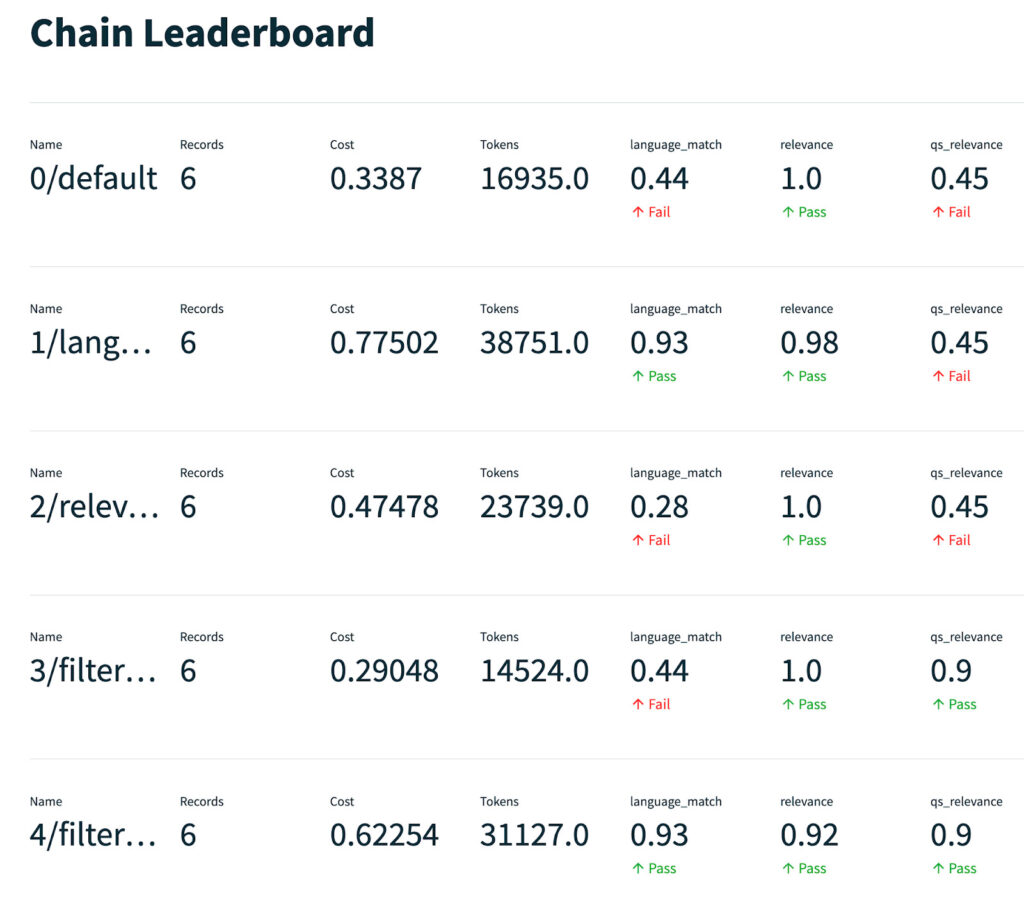
Figure 8: The Leaderboard shows the quality of chains across records as scored by various feedback functions. Chain 4 incorporates both the language prompt adjustment and the context filtering step.
While in our running example, we start with one app version, you could also experiment with various choices in building your app, e.g. LLMs to call out to, hyperparameters to play with, such as the chunk size to break your documents down to in order to compute embeddings to store in a vector database, and more. You would then run all these app versions through Steps 1-5 to evaluate and track your experiments to select the best version.
Try TruLens today
TruLens is free, available today, and ready to help you evaluate and track your LLM experiments. TruLens increases developer productivity while offering greater visibility and confidence in the quality of LLM applications. We hope that you give it a try, give it a Github star, and let us know how it’s working out for you!
Give it a spin: Get TruLens
Give it a star: TruLens on Github
Learn more: TruLens site
Join the community: AI Quality Forum Slack Community
This blog was co-written with Anupam Datta, Piotr Mardziel, and Yuvnesh Modi.
Appendix A: Building a retrieval-augmented LLM app
We built a simple Question Answering app named TruBot in two steps following the widely used paradigm of retrieval-augmented LLMs. This approach grounds the apps responses in a source of truth – a knowledge base.
Step 1: Create embeddings of chunked up documents from the TruEra website (the knowledge base) with an OpenAI LLM and store in Pinecone, a vector database.
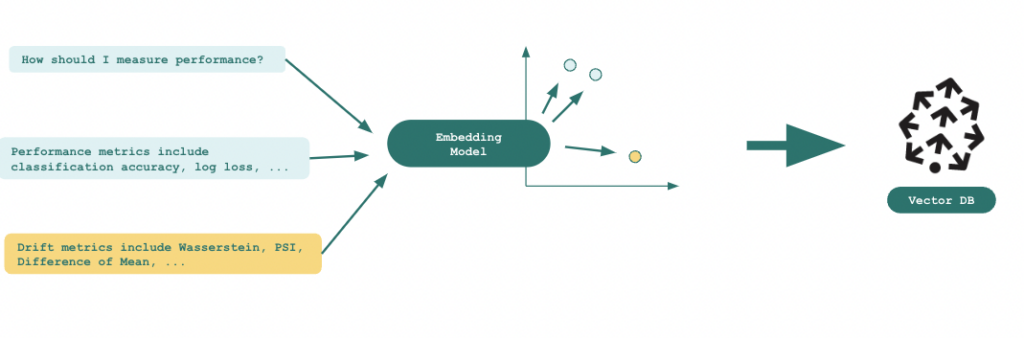
Figure 10: The text on the left are the chunks from documents on the TruEra website. These are converted into embeddings using an OpenAI LLM and stored in the Pinecone vector database
Step 2: Create an app by chaining the OpenAI LLM with Pinecone vector database and use it to answer questions as shown in Figure 3.
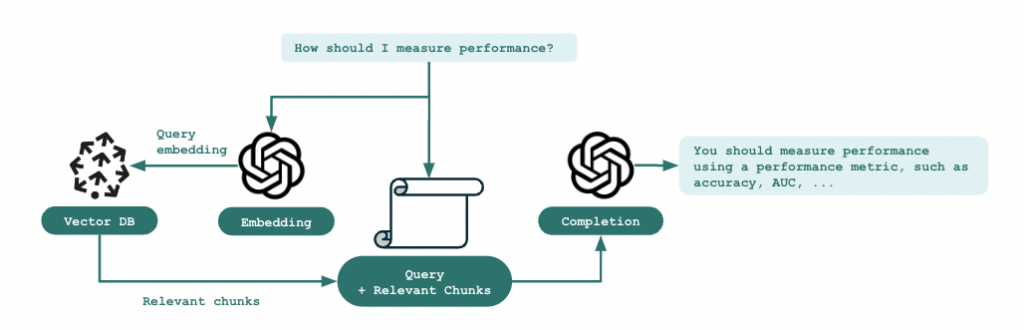
Figure 11: The steps for answering questions using the chained QA application.
Appendix B: Checking for relevance of chunks
The TruBot app was tested with a feedback function that checks how relevant individual chunks retrieved from the vector database are to the question.
The results of this test when asked the question “Who is Shayak?” are shown in Figure 10. The vector database returned 4 context chunks – the first two were individually relevant to the question (they were about Shayak) and the last two were not relevant to the question (they were about a different TruEra employee – Shameek). The final response was affected by the irrelevant chunks – the last sentence in the response includes information about Shameek in answering the question about Shayak.
Notice that the feedback function correctly gave high relevance scores to the first two chunks and low relevance scores to the last two chunks. This information can be used to only send the first two chunks for summarization, thus improving the quality of the final response.

Figure 12: Feedback function scores of qs_relevance, i.e. how relevant individual chunks are to the question.