
Achieving high AI Quality requires the right combination of people, processes, and tools.
In the last blog post, we introduced the processes and tools for driving AI Quality in the early stages of model development – data quality assessment, feature development, and model training.
This post continues deeper into the lifecycle and covers model evaluation and iterative refinement, model selection, and approval. Like the previous post, we draw attention to steps where high impact failures occur and discuss how you can overcome these typical breakdown points by augmenting your processes and leveraging emerging tools. Let’s dive in!
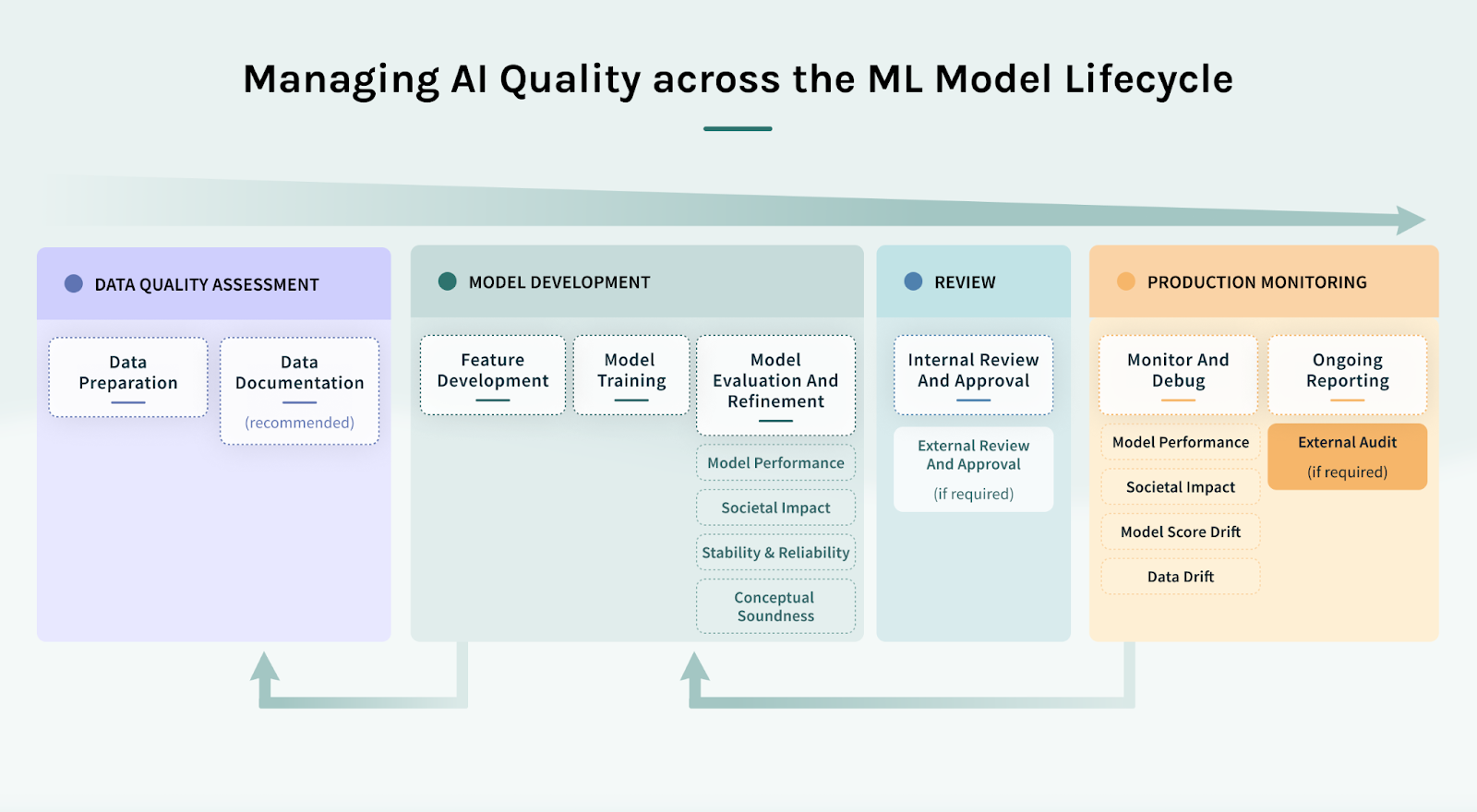
Today’s post covers the evaluation, refinement, selection, and approval process of the lifecycle.
Evaluate and Refine Models
Once a set of first-cut models is trained for a task, the next steps are to:
- evaluate these models and associated data along a number of AI Quality attributes
- discover weaknesses
- and iteratively refine models and data to improve their quality.
The evaluation involves running a battery of customizable tests for AI Quality attributes spanning model performance, societal impact indicators, and data quality (see this post, “What is AI Quality? A framework” for more details). The test results summarize model strengths and weaknesses across these attributes, and inform action to refine models and data.
The model development and refinement phase is a key area for AI Quality Management. This is where traditional data science processes are being dramatically augmented and improved as new tools, such as TruEra Diagnostics, are adding significant value.

Key model tests in the evaluation and refinement phase
Model performance
- Model accuracy metrics capture how on-target a model’s predictions are, by comparing eventual ground truth data with the original prediction. For example, consider a model that is assessing applicants to decide whether they are sufficiently creditworthy to receive a home mortgage. An accuracy test would automatically compute metrics such as accuracy, AUC, or GINI scores, based on who ultimately is current on their mortgage payments.
If these accuracy metrics perform below a certain threshold, it is very useful for data scientists to have tools that allow them to systematically isolate the root causes of the problem and get guidance on improving model accuracy. Ideally, these tools would seamlessly integrate into their workflow. This root cause analysis has historically been a gap in the tool chain for data scientists.
Recent advances in this area support data scientists by tracing model problems to issues of data quality (e.g., errors in labeling of data or, sample selection bias), weaknesses such as overfitting, or pipeline bugs. The diagnosis can also be coupled with directed mitigation techniques to improve the model. For an example, we present a methodology and an illustration with a home mortgage model in this article, “How to Debug ML Model Performance.”
- Conceptual soundness refers to how well the model’s learned relationships will generalize when applied to new data, such as when it is launched in live use. For example, a model for mortgage risk assessment that has learned that a combination of the age of a loan and its cumulative lifetime value is a good predictor of default risk will likely be conceptually sound when it’s launched in the UK mortgage market. In contrast, a facial recognition model that uses the color of the background to identify a face as belonging to Tony Blair is unlikely to generalize well.
A special case of conceptual soundness is robustness. It captures the idea that for certain types of models, such as facial recognition models, small changes in inputs should not dramatically change model outputs.
Conceptual soundness tests include
- automatic testing for robustness;
- surfacing how model outputs depend on features through sensitivity analysis (e.g., showing that credit risk reduces as income increases up to a certain income level and then stays flat with further increases in income); and
- identifying important learned concepts that are driving model predictions (e.g., lesions in an eye causing a model’s prediction for diabetic retinopathy in a medical image analysis model).
Note that assessment of conceptual soundness will often require a data scientist or subject matter expert to make a judgment, with tools assisting in that process, on whether the relationships learned by the model will generalize well.
- Drift refers to a set of phenomena surrounding machine learning that reflect changes in the data distribution being fed into the model (data drift) or to the relationships between the input features and the target variable (concept drift).
It is a central AI Quality attribute because machine learning often relies on a key assumption that the future will be like the past. In the real world, this is very rarely the case, thus causing the performance of models to degrade over time. A recent example of (concept) drift in machine learning comes from Zillow’s iBuying models, which over-estimated home prices, likely because they failed to recognize that the housing market had cooled down relative to the time when the models were trained.
Effectively addressing drift requires AI Quality diagnostics and monitoring tools for automatically identifying different forms of drift (e.g., data drift, model score drift, and concept drift), understanding their root causes (e.g. shifts in data distribution of specific features, changes in the real world such as macroeconomic factors relating to the housing market) and providing guidance, as needed, on how to re-adjust the data or model to mitigate accuracy and conceptual soundness degradation from drift (e.g., by dropping some features, upweighting certain data segments, adding in new features to detect concept drift more easily). For a more detailed presentation on this topic, we refer the reader to the article Drift in Machine Learning.
Societal impact
- Fairness (also sometimes called unfair bias) is concerned with ensuring that machine learning models do not introduce or accentuate unfair biases in society, such as those related to gender, race or other characteristics. This involves data scientists and subject matter experts performing the following key steps assisted by AI Quality tools:
- Identifying potential unfairness by measuring fairness metrics, such as statistical parity in outcomes across groups (e.g., ensuring men and women are approved at similar rates for loans or job interviews) or that a model’s error rates across groups are comparable. A tool that assists in this step needs to have comprehensive support for fairness metrics and groups, as well as provide guidance on which metrics are appropriate for specific use cases.
- Performing root cause analysis to determine whether the identified statistical unfairness criteria are indicative of actual unfairness. This step is key. Just because a statistical fairness metric indicates a potential problem, does not mean that there is a problem with the model. For example, a model may be approving women at a lower rate than men for loans because of differences in their income level. In this case, the model may not be engaging in unfair discrimination and may be fit for use (although there may be other structural problems, such as gender pay gaps, that may need to be addressed through other channels).
- Employing a targeted mitigation strategy. A root cause analysis could also surface that there is indeed a fairness problem with a mode. For example, in a hiring model, disparity in outcomes for women relative to men could be traced to differences in continuous employment history. One could in such a case make the judgment that this feature is a proxy for gender, since historically women take more time off from work to take on child rearing responsibilities, and in fact this feature should be dropped. In some cases, a root cause analysis could surface that error rates are higher for minority groups and a mitigation strategy could involve balancing or augmenting the training data to ensure that the model performs comparably across groups.
We refer the reader to the article Designing a Fairness Workflow for Your ML Models for a more detailed view of what an AI Quality tool-assisted fairness workflow could look like.
- Transparency ensures that meaningful information can be generated on the way in which the model makes predictions or decisions. Such transparency could be needed for those impacted by a model’s decisions (e.g., a job applicant whose application has been rejected by an automated recruitment system) as well as stakeholders within an organization who must stand behind the conceptual soundness of the model’s decisions (e.g., the hiring manager using the recruitment system). A detailed view on both external transparency (the first example above) and internal transparency (the second example) is presented in this document.
- Privacy ensures that the use of personal data as inputs into the model is within legal, contractual and the organization’s self-defined ethical boundaries, and that the outputs of the model do not result in unintended breaches of privacy (e.g., leveraging differential privacy).
Data quality
Data quality refers to the attributes of a dataset used to build & test models that impact model fitness, including missing data, and data representativeness, as well as quality of production data. Data scientists and engineers perform certain data quality assessments before building models as described in the previous blog in this series, “AI Quality Management: Key Processes and Tools, Part 1.” However, an important and often ignored class of consequential data quality assessment can only be done after a model is trained.
Consequential data quality assessment
While examining the quality of datasets in isolation is absolutely necessary, it is also critical to study data quality in the context of the models in which the data are used.
For example, consider a machine learning model that is setting prices for retail products. Suddenly, the model performance drops. A tool-assisted root cause analysis surfaces that a specific set of features are driving the model’s performance degradation. A closer look reveals that for two of those features, their encoding is broken. The data values for those two features are thus of poor quality and that is consequential – it is the cause of the performance drop. This information can also guide the data scientist to fix the problem.

In contrast, some of the potential data quality issues surfaced by traditional methods may not be consequential. For example, consider a data set being used to train a credit model. It has an imbalance across gender on the marital status feature: the proportion of married women is significantly lower than the proportion of married men. However, since the model does not rely much on this feature, this imbalance is not consequential to the model’s accuracy or fairness characteristics.
This form of consequential data quality assessments are growing in importance with the adoption of complex machine learning models trained over high dimensional datasets. Consequential data quality is evaluated using AI Quality tools.
Select Model
The model selection process leverages the results from the previous step of evaluating and improving models along various AI Quality attributes. Historically, the model selection process in many domains has focused on picking a model or a small set of models that provide the best accuracy metrics. These models may then be subjected to an A/B test before one is finalized and moved into production.
While accuracy continues to be an important AI Quality attribute, we are starting to move to a world where the model selection process leverages a deeper and broader evaluation of models and associated data. A key new step is to compare the candidate models not just on predictive accuracy but also other AI Quality attributes, such conceptual soundness, drift, error analysis, transparency, and fairness, and then choose a model (or small set of models for A/B tests) that provides the best overall balance across these attributes.

Review and Approve
Finally, once a model is selected for deployment, it is subject to a review and approval process. This step requires communication of the model evaluation and selection results to data science managers, and often to other stakeholders in business or risk functions. For certain verticals and use cases, such as high risk models in financial services, the review and approval process may involve an independent model risk management team that reproduces and validates the work done by the data science team summarized above. Relatedly, fairness assessments are sometimes conducted by separate teams that involve legal and policy people in addition to data science experts. Key additional tooling requirements for this step are capabilities for reporting and interactive dashboards that are accessible to these user personas.
This blog concludes the overview of the steps to manage AI Quality through development and approval. The next blog will cover an often-missed but critically important part of managing AI Quality – production monitoring.