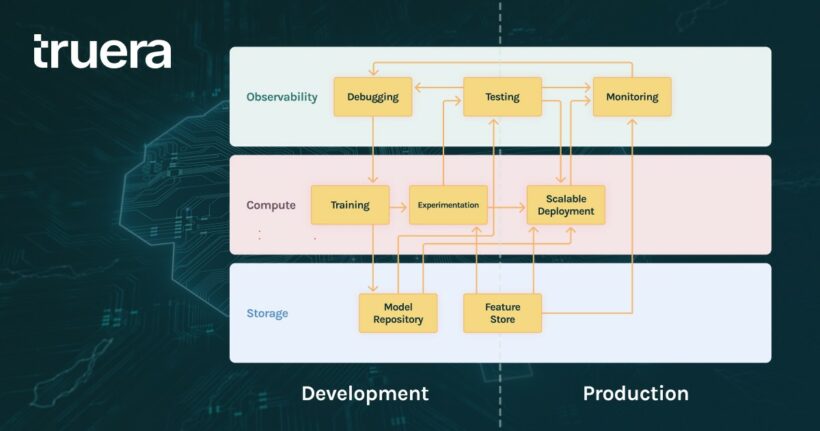
As AI adoption increases, Machine Learning platform teams are tasked with building an MLOps stack, focused on automating and monitoring all steps of the ML workflow. In this article, based on our experience in scaling and seeing over 100+ teams successfully scale their MLOps stacks, we’ll describe how to progressively build an MLOps stack to help support your data science team as they scale their work. In particular, we’ll also focus on building out stacks that contain an observability layer for testing, debugging and monitoring models throughout the lifecycle of a model that is often overlooked. The observability layer allows one to manage AI quality throughout the lifecycle, optimizing for the system’s real world success. It includes model performance analysis, explainability, fairness, data quality and model comparison capabilities.
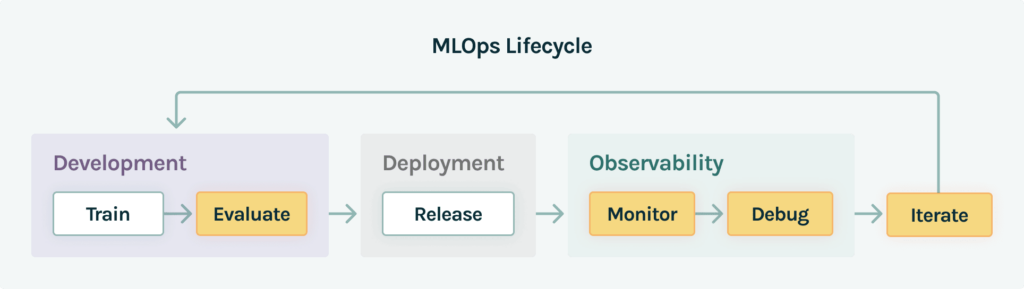
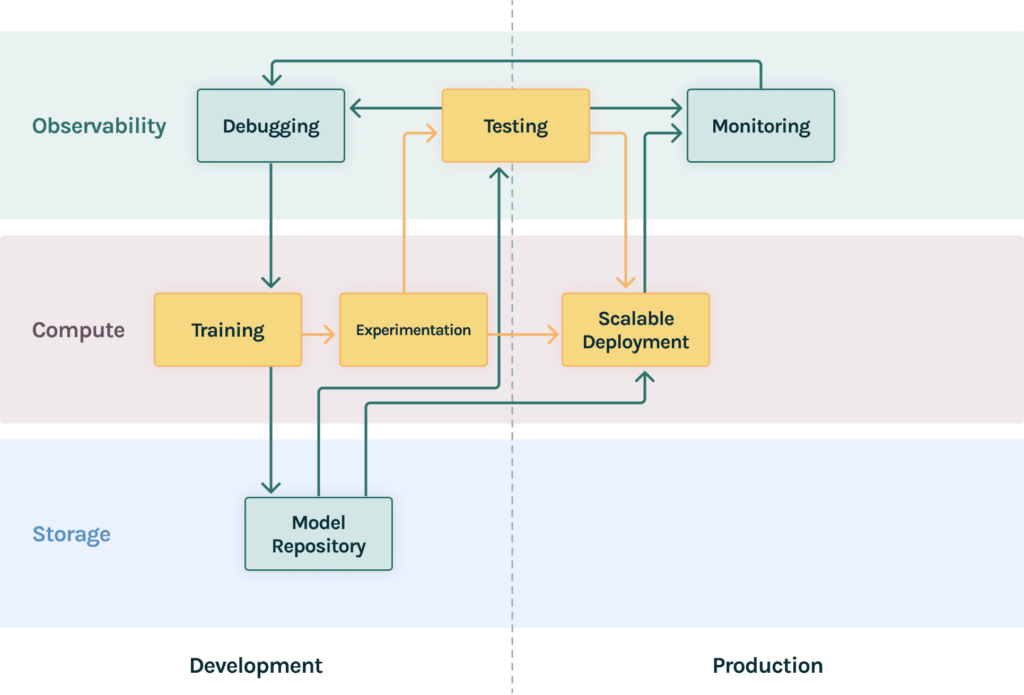
As companies grow their data science capabilities, it’s critical for MLOps teams to support their data science teams with the right tooling. Here’s a simplified view of the MLOps lifecycle as a model moves from development to production.
Having a stage-appropriate MLOps stack can enable data scientists to move faster and build higher quality models. But, before we get going, let’s talk about the three key layers of a data science stack as useful structural tool:
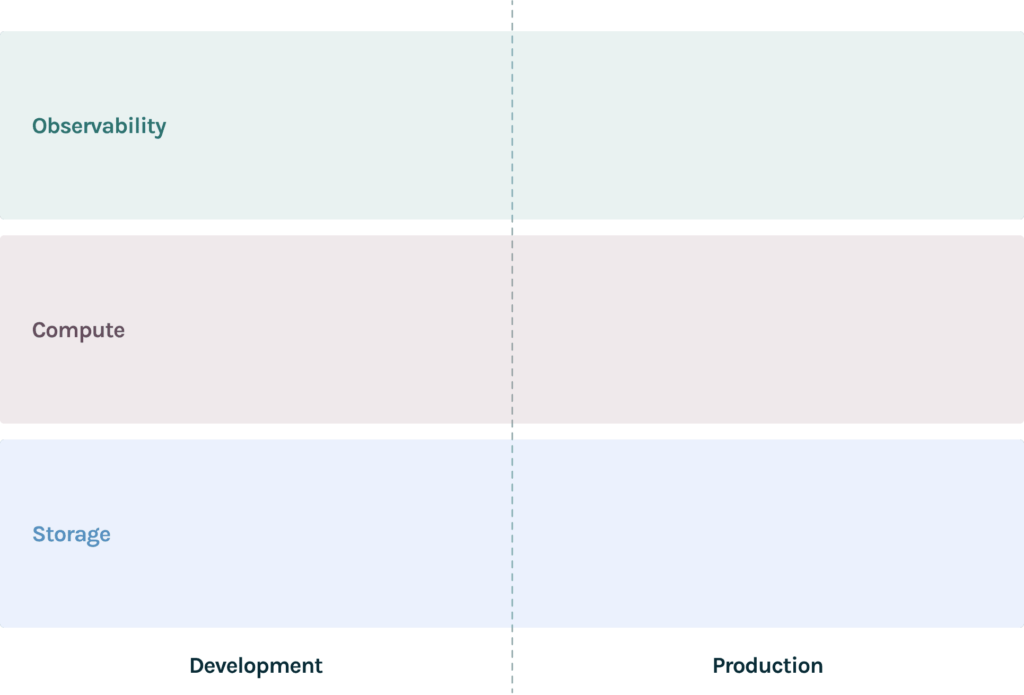
It is useful to view the stack in two dimensions: 1. functions and 2. lifecycle. Functions are clustered into three layers while a model life cycle includes two main phases separated by the dotted line in the diagram above.
MLOPs functions:
- Storage: The storage of the stack is the infrastructure for storing, organizing data and models.
- Compute: The compute layer is the infrastructure for accessing compute resources to scale training and serving.
- Observability: The observability layer provides infrastructure tools to test, debug and monitor the performance of models at scale. We find that teams that prioritize observability early in their MLOps journey enable their teams to move faster with far fewer production issues.
ML model lifecycle:
- Development: In this phase data scientists build, evaluate and iterate on models till they are happy with the results.
- Production: Once models are put into the real world, data scientists need a new set of infra tools.
Considering the large number of tools available out there, it’s possible to over engineer your MLOps stack. Here’s what we’ve learnt while working with teams of different sizes, about how to right-size your stack for the right state of maturity.
1 Data Scientist
You’ve just started things off on the machine learning journey. At this point, your first data scientist is likely trying to figure out the first use cases in the company, and spending time exploring different approaches. It’s important to quickly build model prototypes and prove value before diving too deep into optimizing tooling. At this point having mature MLOps can get in the way, and it’s better to let data scientists use tools that they know and love.
2-10 Data Scientists: Efficiency and Quality
With a small and agile data science team, it’s important to start providing some structures to enable teams to efficiently create resources and put in place shared best practices to enable quality.
In order to do this it is useful to put in place:
- Training and Experimentation: A shared experimentation environment such as Jupyterlab, Vertex AI workbench, or Sagemaker notebooks means that data scientists can quickly spin up environments to try out new ideas. Training can often be resource intensive, and it can be time-consuming for data scientists, provisioning training infrastructure powerful enough to run real experiments. Integrating a powerful distributed kubernetes or spark based training environment that is integrated with the experimentation platform can hugely speed up data science.
- Deployment: This can also be a good time to standardize model deployments using basic model serving tools depending on whether your AI powered applications expect your models to be online or batch.
- Testing: As more models start to make it to the real world, at this point it is critical to make sure data scientists have the right infrastructure to test models both during development and before production. Taking a test-driven approach to development can mean that teams can share test suites to encourage quality to measure what’s important for your applications. This includes performance, drift, explainability, fairness and more. These test suites can also be reused for continuously testing new datasets, and new model iterations to enable CI/CD for your AI.
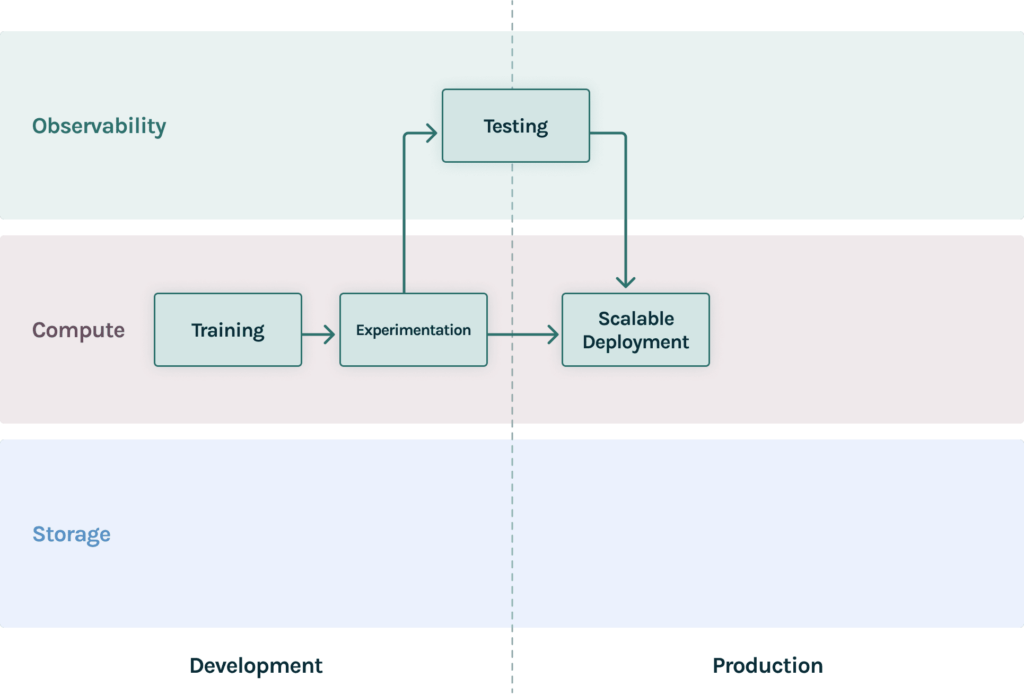
10-50 Data Scientists: Different Dimensions of Scale
As the data science organization grows from 10-50 data scientists across multiple teams, platform teams need to start scaling their capabilities in a number of different dimensions:
- Model repository: As the data science team starts churning out models at a rapid rate, you need a single source of truth for all models that’s not a spreadsheet. The training platform writes every model to the repository and then it’s used for unified testing and deployment.
- Scalable deployment: The model serving platform now likely needs to scale to a wider range of model types (think R, Python, Java, Tabular Neural Networks) and a larger volume of data.
- Monitoring: As your model serving needs scale, so does your monitoring. Here are a couple of key considerations:
- Self serve monitoring: As your data science team grows, the platform team will have limited context into the different models that are running. In order to effectively empower data scientists need to be able to set up quality checks for their deployments independently, and also get alerts for them so that they can respond to issues with velocity.
- Scale: It is important for the monitoring platform to be able to track performance across different deployment platforms and model types, and also be able to do that responsively across high volumes of batch and online data.
- Integration: The monitoring platform should be closely integrated with a platform for: testing (model performance tests should be the basis for production alerts); debugging (when issues arise, data scientists should be able to rapidly identify root causes); and deployment (logging production data should happen as close as possible to the serving system which is the source of truth).
- Debugging: As mentioned above, one key aspect of making debugging self-serve is that data scientists should be able quickly identify the root causes of data which often involves tedious digging through production data. Debugging tools provide data scientists surgical precision on identifying root causes of model problems both during training and production.
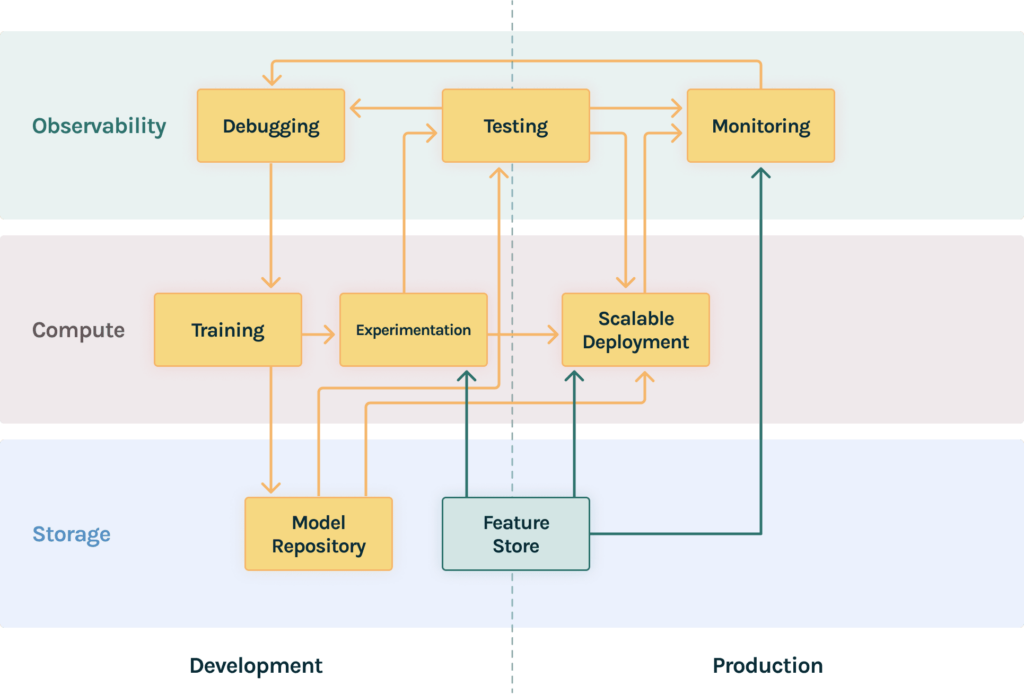
50+ Data Scientists: Even more Scale, Feedback and Collaboration
At this point platform teams are likely to be distributed across different data science teams, and this requires taking things to the next level. Data science teams often start adding tools to get a handle on the sprawl of use cases across teams.
- Feature store: A feature store becomes a single source of truth for data that is available to data scientists across the organization. This visibility enables reuse of ideas and concepts beyond what’s just possible with a model repository. The feature store also needs to be connected to the training and experimentation platform, the deployment platform to serve data and the monitoring platform to enable the monitoring of data quality.
- Testing and Monitoring: At this point, it is quite likely that different teams will need to use different platforms for training and deployment that are best suited to their needs. Testing and monitoring need to scale across different platforms that different teams may use. You may have some teams use H2O and others use Google Vertex. A unified observability layer across these ecosystems is critical to maintaining consistency in quality across the data science organization.
- Retraining with Debugging and Feedback Loops: This is also often a time where data science teams need to implement better feedback loops and linking that to a debugging tool is critical in ensuring that you are retraining with the right feedback and at the right time. Retraining automatically needs good feedback loops. Blind periodic retraining can end up being either too infrequent or too expensive.
Conclusion
While every organization is different, in this blog post, we walked through the ecosystem of machine learning tooling based on our experience working with teams that have scaled their data science organization successfully. While there is no single canonical way to build out an MLOps stack, we hope that this guide can help platform teams think through the considerations of what to build when and the importance of building quality early. Try out TruEra for testing, debugging and monitoring your machine learning models throughout the lifecycle to build out the observability layer of your MLOps stack.
In a follow-up post we’ll also cover the LLMOps stack, the corresponding MLOps stack for LLM applications that is emerging as we speak. Stay tuned!