LLM use cases are growing up! Large Language Models (LLMs) are well on their way to widespread adoption in a number of critical use cases from hiring, education, and banking. These AI models draw their usefulness from the fact that these are foundation models; they are trained on a vast quantity of data at scale that can be adapted to perform a wide variety of natural language processing (NLP) tasks that were previously only thought to be solvable by task-specific models.
Yet, LLMs have also raised various concerns because they could hallucinate and are susceptible to bias. Some AI industry leaders have even called for a 6 month moratorium on the development of more powerful AI systems during which the AI community could implement appropriate safety protocols and governance systems. More fundamentally, these models are so massive and versatile that their behaviors are hard to anticipate; and when they misbehave, they are harder to debug. Therefore, maximizing the benefits of LLMs while mitigating their risks is very challenging.
In a previous post, we explained how to assess LLMs performance across downstream tasks. In this piece, we look at the question of when LLMs should be evaluated, providing practical advice to app developers using a concrete use case. Then, we draw some governance implications.
The challenge
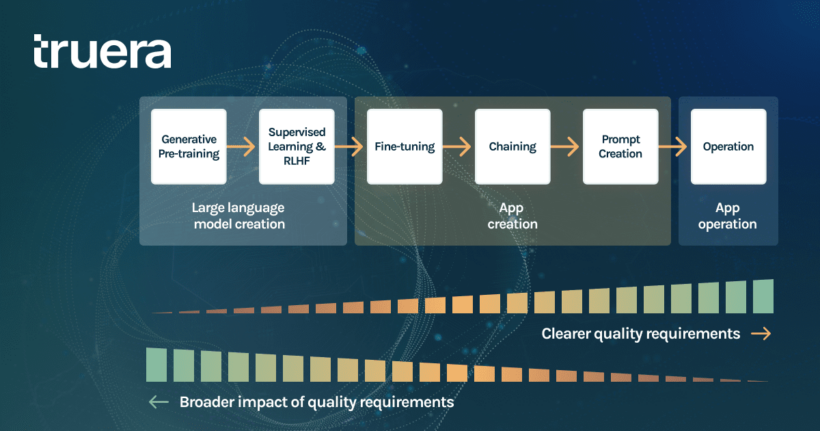
To discuss when to evaluate LLMs, let’s pick a concrete use case. Assume you want to build a recruitment app powered by a LLM that matches resumes to job postings. Let’s look at all of the steps that go into developing the application ‘from scratch’. The first three are typically done by an LLM provider, and the last three are the app developer’s responsibility.
- Generative pre-training: An LLM is trained on vast amounts of data to predict the next word after a piece of text. This allows generative language models to be really good at producing human-like text.
- Supervised learning and RLHF: Then, language models are trained on specific examples of human-provided prompts and responses in order to guide their behaviors. One common stage is Reinforcement Learning via Human Feedback. This step (used for example in ChatGPT), involves training a reward model that measures how good a response is, and then uses reinforcement learning to train the generative model with that reward model.
- Fine-tuning: An app developer can choose to refine the large language model using domain-specific data to improve performance. In our use case, this would be text from resumes and job descriptions.
- Chaining: The LLM is often connected to other tools such as vector databases, search indices or other APIs. In our example, this may be a database of resumes and job descriptions to be used by the LLM to summarize.
- Prompt creation: The app developer creates prompts tailored for a specific use case. In our example, this may involve prompts that ask the LLM to create search terms for finding appropriate candidates, and then summarize a set of relevant resumes and linkedin profiles.
- Operation: Finally, the CV-based recruitment app is deployed and recruiters can use it to identify great candidates. At this stage, it may be appropriate to evaluate, filter and modify requests and responses to improve performance.
Intuitively, the more defined is the task at hand, the easier it is to establish quality requirements (i.e. performance, fairness, data quality, explainability and toxicity). To continue with our recruitment use case, while parsing resumes to extract useful information about a candidate’s experience, skills, and past employment to recruit the best talent for a role, you may want to check if your model is consistent with your quality requirements. Yet, intervening when the model is already in operation may be too late to address quality issues that have been built in from the creation of the LLM.
As a corollary, it is harder to establish quality requirements when creating a LLM (stages 1 to 3) because of its versatility. Indeed, the same LLM can be used for the translation of legal documents, sentiment analysis of customer reviews, or chatbots for insurance claims; each of which has context-specific quality requirements. As a result, it is important to think about quality at all stages of an application’s lifecycle (see figure 1).
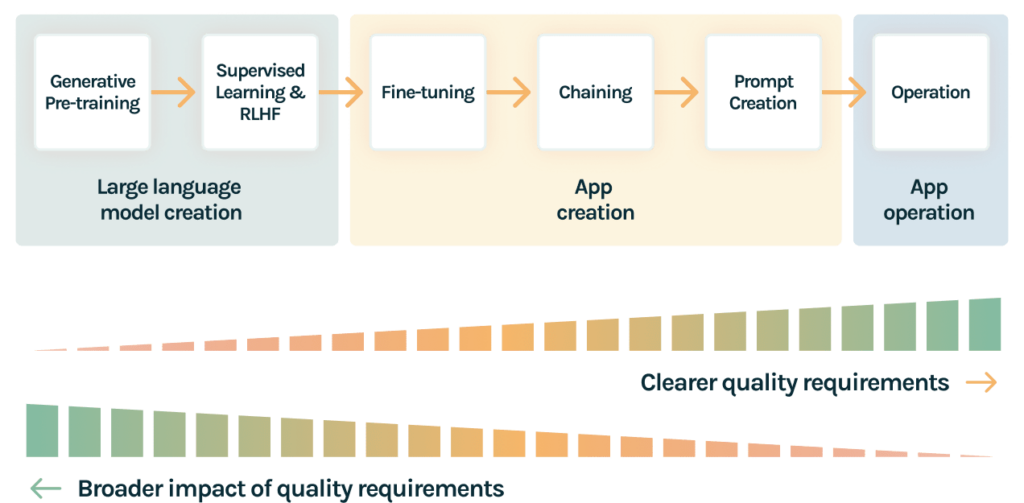
Steps to Evaluate the recruitment App
In order to ensure that the recruitment App is trustworthy, meaning that its behavior is consistent with specific quality requirements, LLM and app developers need to account for quality across all of the steps outlined above:
- Generative pre-training: First, it is important to train on a text from a diverse set of sources. At this stage, including data with potentially undesirable behaviors such as toxicity can help explicitly avoid such behaviors in the later stages of the model.
- Supervised learning and RLHF: Then, the model can be exposed to a large variety of curated examples that not only help the model perform better, but also be more aligned with human expectations. For example, the model can be taught to not assume pronouns based on profession, and penalize other potentially toxic behaviors in the model. Some of the data can also be used to encourage models to follow instructions or perform more chain of thought reasoning.
- Fine-tuning: Third, it is important to capture domain specific data. In our running example, this could be a larger set of resumes and job descriptions. It would also be important to ensure minority classes are well represented. The considerations at this step are similar to those at generative pretraining.
- Chaining: Fourth, the quality of the application results directly depend on the results from the other components in the system. For example, if the database queries return irrelevant resumes, the resulting output will likely be inaccurate..
- Prompt creation: Fifth, the way a model is prompted can have a very significant impact on the model’s responses. For instance, in this paper from Anthropic, researchers show that LLMs may be able to self-correct and avoid producing harmful outputs in various situations, if prompts are written appropriately (see figure 2). During the prompt creation stage, as you experiment, it’s important benchmark improvements in performance, and fairness. This can be done at scale by defining appropriate feedback functions and running them systematically on test datasets.
- Operation: Finally, when the model is exposed to real world requests, it can always encounter unexpected inputs and underperform. As a result, It is important to monitor models for quality, continuously measure bias, and assess the relevance of responses. Here again, feedback functions could play a critical role by allowing you track LLM performance over time or compare different LLM versions.

Governance implications
Regulators are concerned that the use of AI-based tools in workforce management may end up widening employment disparities between demographic groups and have taken action to mitigate this risk. In the United States, the New York City Council passed a bill that requires employers to conduct annual bias audits of Automated Employment Decision tools, including those supported by machine learning. In the European Union, the EU Parliament has recently adopted the Artificial Intelligence Act, a regulation that classifies the use of AI for workforce management as high-risk and thus subject to quality management and conformity assessment procedures. The Act also requires that generative AI systems, including LLMs to disclose when content is AI-generated, don’t generate illegal content and publish summaries of copyrighted data used for training.
Organizations should not simply react to these regulations but should proactively build capabilities to ensure that their LLM-powered apps are trustworthy. This would not only reduce their regulatory exposure while fostering trust with their various stakeholders. To achieve this, they should run all their models through a comprehensive evaluation and monitoring workflow structured around four key steps:
- Evaluate LLMs: LLM developers should continuously benchmark their models and check if their models are consistent with their quality requirements (e.g. accuracy, fairness, data quality, robustness, security and toxicity, etc). The HELM initiative attempts to provide a wide set of benchmarks to evaluate language models against.
- Document LLMs. Such documentation should include information about pre-training datasets, quality test results (e.g.performance, explainability, fairness, etc.), and prompt engineering approaches of LLM developers. Downstream app developers and regulators should have automatic access to this documentation.
- Evaluate LLM-powered apps. When developers start building apps leveraging an LLM, they must perform additional quality evaluations. These evaluations are similar to those performed by the LLM developer (e.g.accuracy, toxicity, fairness, etc), this time using domain-specific data and prompts. TruLens is an open source evaluation framework that lets app developers set up application specific feedback functions and also collect human feedback to track the quality of their LLM applications.
- Monitor LLM-powered Apps. The real world is full of uncertainty, therefore it’s common for production data to deviate from training parameters over time. If model quality issues are not continuously addressed, models can drift or perform poorly when used in production. Therefore, it is essential to monitor LLM-powered Apps for quality, and measure their overall performance (i.e. accuracy, bias, robustness, stability, toxicity, etc) on an ongoing basis. Here again, we suggest using feedback functions.
The way forward
The advent of LLMs is truly remarkable and is poised to unleash a new wave of innovation in the tech world. Yet, their potential can only be fully realized if they are trustworthy. Various efforts are underway in the tech industry to achieve this goal and we are convinced that implementing a comprehensive evaluation and monitoring workflow is an important step in the right direction. Currently, we’re testing this approach with a few key partners and should update our framework based on these key learnings. Stay tuned!
This article was co-authored by Lofred Madzou and Shayak Sen.