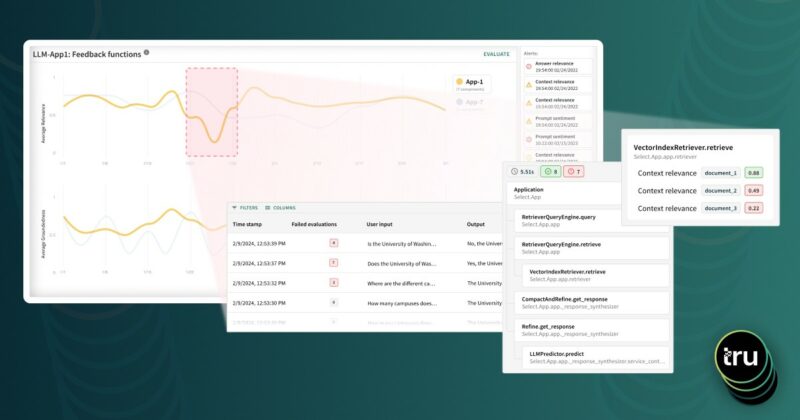
TruEra recently announced the launch of a major update to its AI Observability offering. This launch dramatically expands TruEra’s LLM Observability capabilities, so that it provides value from the individual developer all the way to the largest enterprises, across the complete LLM app lifecycle. A developer can get started for free with the TruLens LLM eval solution and transition seamlessly to using TruEra for LLM Observability in production, at scale, collaborating with a broader team. We are seeing significant increases in the use of the TruLens (2-3x month over month) and are grateful for the positive feedback we’ve gotten from organizations actively using TruLens, like Equinix and KBC Group.
We are at the advent of a new era in software
We are at a critical time in the evolution of GenAI technology for the enterprise. GenAI is a paradigm-shifting technology like predictive AI, SaaS, mobile, and other large evolutionary stages in software and computing. But the full extent of the impact on the enterprise and how quickly it achieves this full impact is still uncertain. In 2023, most enterprises developed prototypes and ran internal POCs, and were charged with enthusiasm about GenAI’s potential. We are at a critical point – will this enthusiasm sustain and prove itself worthy, or will an embarrassing parade of unready apps create a major deflation?
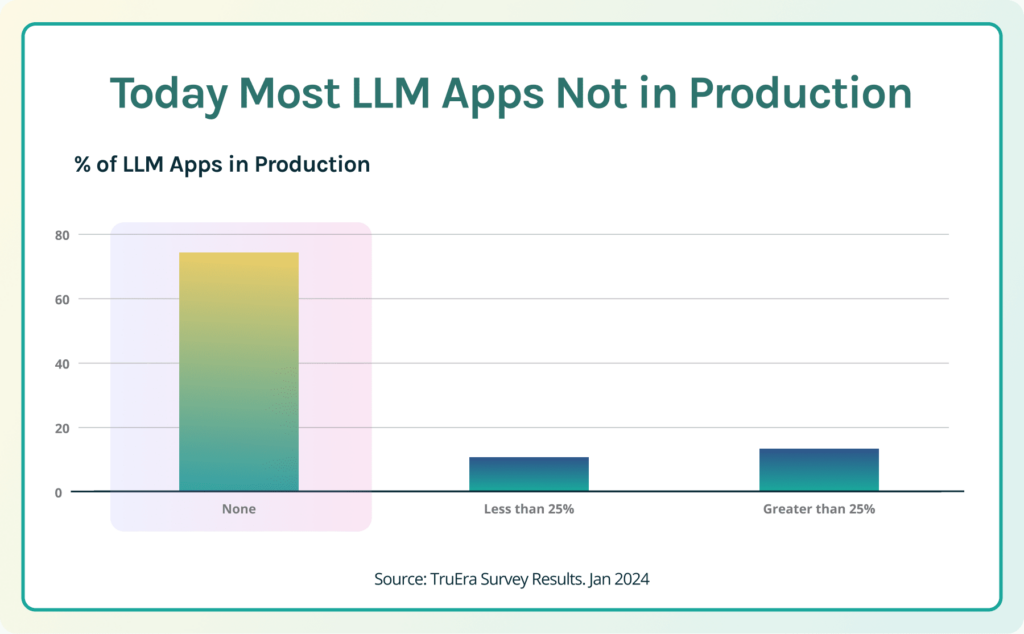
In late 2023, we conducted a survey that showed that very few organizations had actually moved LLM applications into production. Only 11% of enterprises had moved more than 25% of their GenAI initiatives into production. Approximately 70% of enterprises have not yet moved any applications into production. Customers tell us that, now, their top priority is to get these apps into production and to achieve business impact. They want to take advantage of this path-breaking technology and stay ahead of their competition. The questions that these customers and the industry face are fundamentally: How can these LLM applications quickly become successful and fulfill the promise of GenAI? Which factors will determine the ultimate success of these applications?
The unique challenges of LLM applications
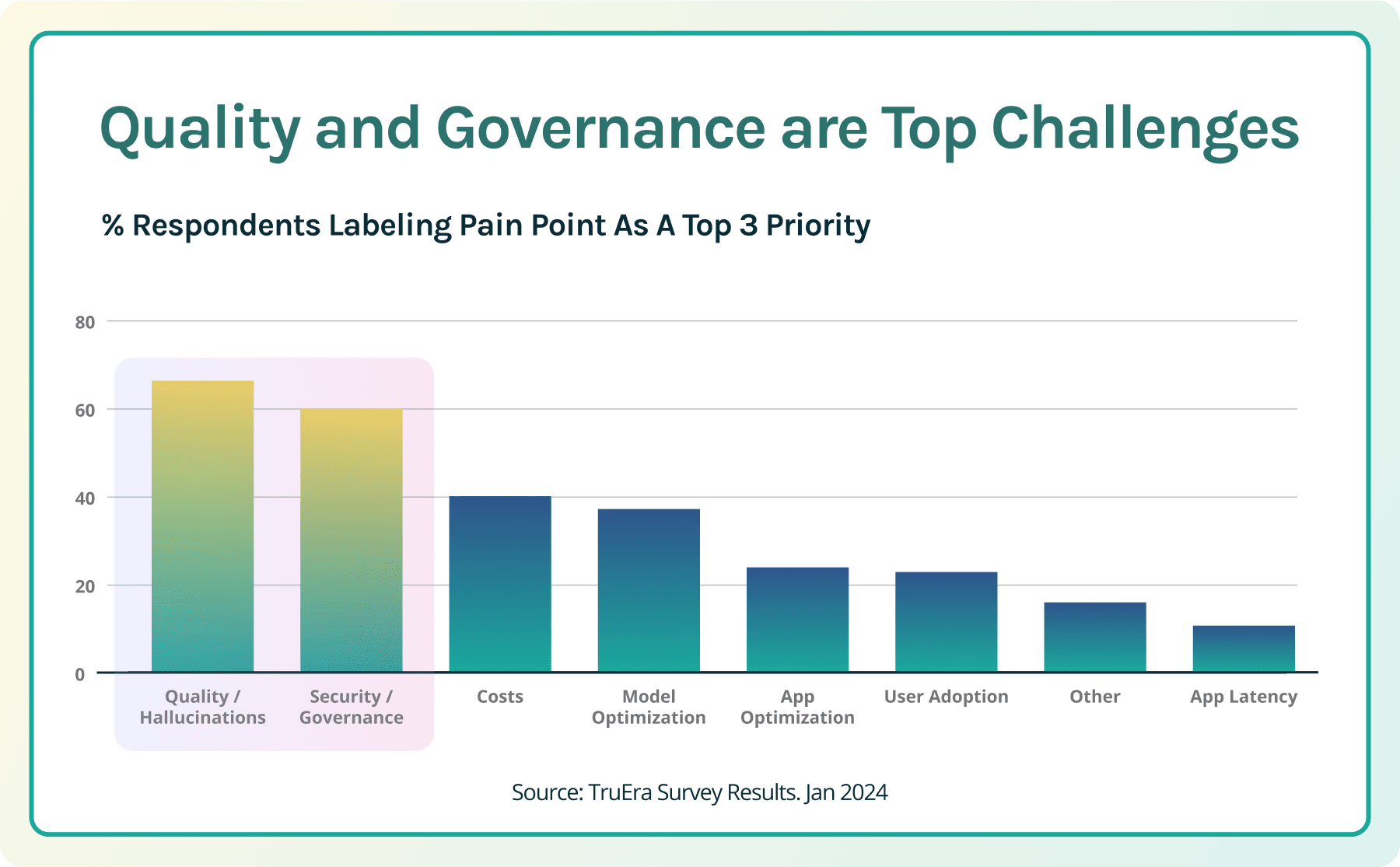
As enterprises and startups get serious about moving LLM applications from the POC stage into production, they experience new pain points. TruEra surveys show that by far the top pain points are quality and governance. Providing a high-quality user experience is key to the success of any application, and LLM-based applications create unique quality considerations, different from other applications. Most software systems, such as CRM systems, tend to be deterministic, providing expected and reliable output based on a given input. LLM apps are less understood and deterministic, producing unexpected and potentially problematic output.
Here are the key concerns that we hear about:
- Relevance and accuracy. In particular, developers need to ensure that LLM apps provide relevant responses, such as an accurate response to a question, or a comprehensive and appropriate summary of content. The LLMs powering these applications have been shown to both provide non-relevant answers (things that may be true, but are not the answer to the question) and to hallucinate, to provide made-up non-factual output. In order to be trustworthy and minimize corporate risk, LLM apps need to meet relevance and accuracy benchmarks.
- Inappropriate behavior, toxicity, or bias. In order to protect their brand equity, stay in the favor of their customers, and to ensure compliance with regulations, organizations want to ensure that their LLM apps are not inappropriate, rude or unfairly discriminatory.
- Leaks or misuse of confidential, personal, or other sensitive information. Enterprises are concerned about sending company proprietary information outside of their companies, such as to LLM providers, as part of operating these applications. They are also concerned about risks related to the output of these applications, including leaking confidential company information, or information that they are legally required to restrict, such as sharing private customer information.
- Cost containment. As the usage of these applications scale, developers also become concerned about costs. For example, variable costs related to usage of the LLMs especially that are low at an aggregate level during an internal POC can rise substantially as the usage of the application increases. Enterprises are also concerned about optimizing their application, usage, and latency but to a lesser degree than the top 3 pain points.
- Ongoing quality management needs. Quality is constantly changing due to changes in inputs. LLM app developers are going to find that addressing relevance and other key performance metrics will be an ongoing battle, as users enter prompts that they did not anticipate, and the underlying content in LLM app knowledge stores changes.
To the rescue: programmatic LLM Evaluation and Observability
How are enterprises addressing quality, governance, and cost challenges? Currently, developers run manual tests, assess quality, watch for governance issues, and calculate costs. This manual approach is limited, time consuming, and painful. It negatively impacts developer productivity, reducing the speed at which developers can improve quality and address stakeholder concerns. In addition, manual methods will, inevitably, miss many quality or governance failures, leading to quality problems during testing or POCs, and reduce trust. Organizations are rapidly recognizing that addressing quality, governance, and cost challenges requires new, programmatic evaluation technology during development and production. Or, as Greg Brockman of Open AI put it: “Evals are surprisingly often all you need.”
And these evals are not only needed during development for testing, debugging, and iterative improvement, but they are also needed on an ongoing basis during production. Enterprises thus need both evaluations and observability.
- LLM Evaluation. Evaluations are critical for identifying quality and governance issues during development, identifying root causes, and then iteratively improving the application. Evaluations address quality and governance issues, all while also managing costs, such as the token cost of using the LLMs. Programmatic evaluations supercharge this by allowing developers to evaluate LLM apps much more quickly, efficiently, and effectively.
- LLM Observability. As developers seek to move their applications into production, they will need to programmatically evaluate their applications on an ongoing basis. The inputs to LLM apps will constantly evolve. This is commonplace for language apps. For example, Google has shared that 15% of the keywords entered into Google search are new each day. While the number of new inputs might not be exactly the same in Enterprise LLM applications, LLM application developers should expect significant change in most apps. Similarly, the content summarized in LLM applications will change over time, leading to new relevance and hallucination challenges. Risks, such as toxicity and bias, will also remain. Ongoing programmatic evaluations will be critical to detecting potential failures. The new challenge that faces developers will be how to scale ongoing evaluations for production level usage.
TruEra: the solution for LLM evaluations in development and production
With our new release, TruEra now provides a comprehensive solution for programmatically evaluating and monitoring LLMs across both development and production. What’s unique about our approach is that we offer both a leading open source offering and a proven, scalable commercial solution. Developers can start evaluating during development using TruLens for free, and then seamlessly start using TruEra as they need to scale their evaluations in production. TruEra is built on top of our proven, predictive AI solution platform,so that customers can have confidence in our scalability and security.
TruEra offers critical features for evaluation and monitoring including:
- Granular evaluations, including RAG Triad analytics
- In order to effectively evaluate LLM applications, it’s important to run granular evaluations. If a developer were to just run a single evaluation of the relevance of the output of a LLM application, it would not provide enough information to effectively debug the application. Instead, developers need to run multiple, granular applications for each of the application’s constituent parts.
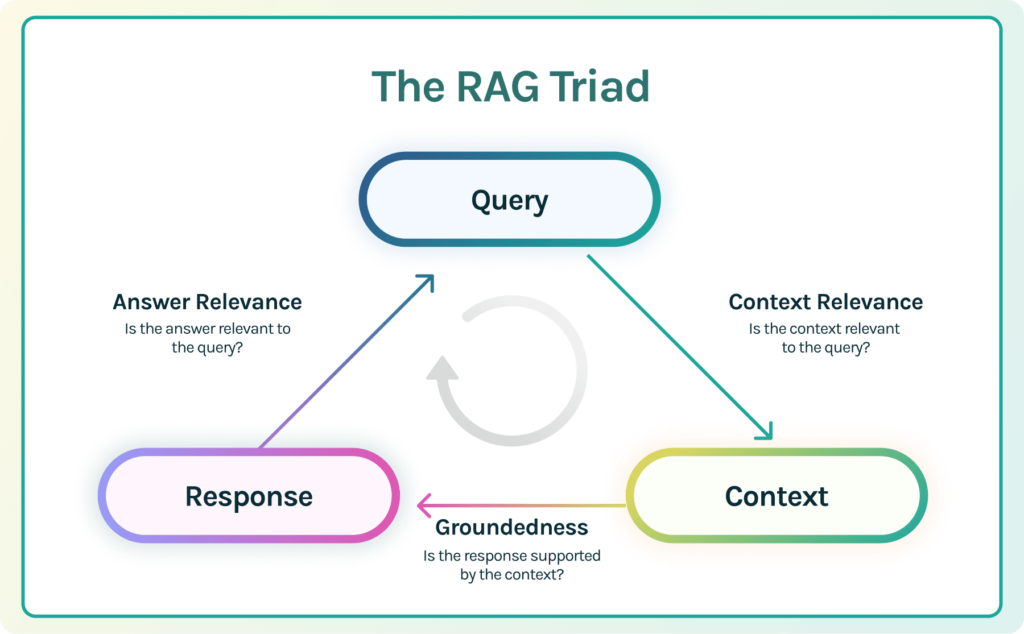
- For example, in order to effectively evaluate and debug a Retrieval Augmented Generative (RAG) application, TruEra created a concept called the RAG Triad. . The RAG Triad requires three granular evaluations:
- Context relevance: assess the relevance of context retrieved by the RAG vector database relevant to the prompt
- Groundedness: evaluates the truthfulness of a LLM summary relative to the provided context, or, in other words, how much the summary may have hallucinations.
- Query relevance: assesses the relevance of the final response relative to the prompt
- These evaluations enable developers to quickly hone in on whether a poor output is due to relevance of the context provided by the vector database, LLM hallucinations, or the quality of the LLM summarization capabilities.
- Comprehensive evaluations for quality and governance
- In addition to RAG Triad evaluations, TruEra offers over 10 additional out-of-the-box evaluations, including: Embedding distanceContext relevance, Groundedness, Summarization quality, PII Detection, Toxicity, Stereotyping, Jailbreaks, Prompt sentiment, Language mismatch, Conciseness, and Coherence.
- TruEra also provides the ability to add custom evaluations, such as tracking manual evaluations.
- Scalable monitoring and alerting
- TruEra can track evaluation output over time at large scale
- Developers can create sophisticated alerting rules to proactively inform developers when any metric hits problem thresholds
- Custom metric monitoring
- In addition to programmatic evaluations, TruEra can track and visualize custom metrics. For example, a developer might instrument their application to track engagement metrics, such as click-through-rate and time-on-page. These metrics can be imported into TruEra so that developers can visualize them over time and create alerts.
- Debugging
- If a developer observes a period of time with problematic values, they can hone in on a particular time range and then create a data set containing all of the underlying application prompts, responses, and metadata during this period. This makes it easy for developers to identify and debug problematic inputs, outputs, and metadata within the application.
Manage GenAI and predictive AI in one place
TruEra’s evaluation and monitoring solution doesn’t just work for LLM applications. It also provides a comprehensive set of explability, evaluation, model validation, testing responsible AI, monitoring and debugging functionality for predictive ML models. Enterprises can use a single solution for both predictive and generative AI.
Helping developers and enterprises achieve production AI
Most enterprises find themselves at a critical juncture in their generative AI development, and TruEra is proud to offer the first combined open source and commercial offering to help them achieve production AI success. Interested in getting started? Download TruLens LLM evaluation software for free today, or contact us to get started with TruEra.
There is a lot more yet to be done. In particular, monitoring LLM applications will require new lower cost and lower latency programmatic evaluation methods. Current common evaluators will not scale that well. More on this soon!