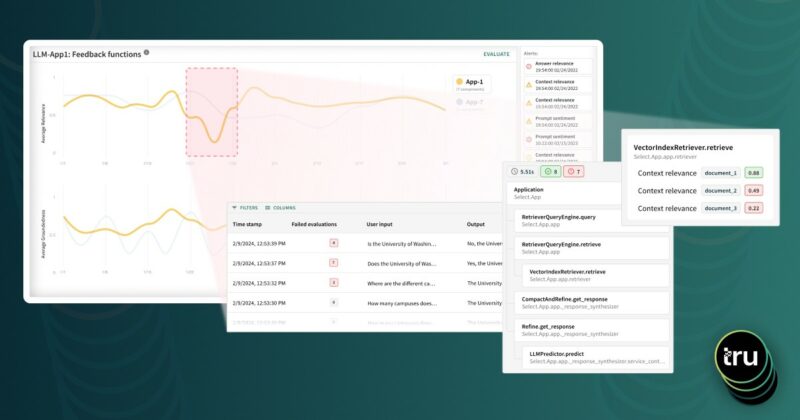
Trust in the quality of machine learning models is key for their adoption in enterprises
Complex machine learning (ML) models are black boxes. That creates a trust problem throughout the workflow in which these models are built, validated, monitored and used. Data scientists do not have sufficient visibility into models to effectively explain, analyze and improve model quality during development and in production. Business users and risk and compliance teams do not understand ML models and their predictions deeply enough to assess model risk, guard against harms like unfair bias, and effectively use models to make decisions.
We are hearing from our customers that the lack of trust in model quality is a pressing, urgent problem that is blocking their adoption of machine learning. Our team has experienced these problems first hand in building and deploying machine learning models for enterprises. And we have tackled these problems head on over many years as faculty and researchers at Carnegie Mellon University.
We have built the Truera Model Intelligence Platform to help data scientists and their business, risk and compliance stakeholders build trust in the quality of their machine learning models. This blog post discusses why the industry needs Model Intelligence, where the vacuum is in the current data-science workbenches, and how Truera fills this vacuum. Please check out our co-founder Will’s blog post for more details of Truera’s launch.
What is Model Intelligence?
We find our customers asking rich questions about their models. Figure 1 captures some of these questions. This broader set of questions is informed by tasks in the workflow in which these models are built, validated, monitored and used. Model Intelligence technology extracts actionable information locked inside machine learning models to answer these kinds of questions.

Model Intelligence enables the deep evaluation of model quality required to build trust in machine learning models. It addresses a major gap in current model-evaluation methods and metrics. It builds on AI explainability technology, which is necessary but not sufficient to provide model intelligence. Let’s delve into the key technology challenges that motivate the need for Model Intelligence: model quality analysis, model comparison and selection, and monitoring.
- Model Quality Analysis

Accuracy metrics like AUC, GINI, F1 scores, RMSE etc., over test or validation data are the gold standard for selecting models before actually testing these in the wild. However, these metrics capture a very narrow slice of model quality. Models with high accuracy can often hide glaring issues just under the surface. Let’s focus on two such issues with model quality: test-production performance gap and unfair bias.
Test-production performance gap. Models, once deployed to production, often perform worse relative to their performance during training and validation. These issues can arise for a number of reasons, including a biased data sample, mislabeled data, incorrectly computed features, overfitting, and various forms of concept drift.
For example, one model we tested had incorrect labels for some high-income individuals due to a fault in the data extraction pipeline. Looking at accuracy metrics won’t reveal this issue. If this model were deployed to production, the model would be grossly inaccurate on the highest value segment for this model. At the moment, a number of teams building and deploying AI models are struggling to train models that would behave well on current pandemic-impacted data, which can look very different from data that is available to train on, which would typically be from a non-pandemic world.
Unfair bias. A growing concern with machine learning models with the increase in complexity of both the models and the data available to train these models is that models might be biased against women or other historically disadvantaged groups. Bias in AI has been widely reported on, and has created much controversy over the use of AI in critical applications such as law enforcement, employment and credit. This problem has been compounded by the fact that the prima facie findings of bias reported in these cases have often not been traced back to any justifiable explanation.
For example, in one of the first systematic studies on bias in AI, our research group at CMU found that men were more likely to see high paying job ads compared to women. In more recent news, Apple’s credit card, issued by Goldman Sachs, was investigated for discrimination against women, when certain women found that they were given much lower credit limits compared to men. Goldman Sachs’ response was: “In all cases, we have not and will not make decisions based on factors like gender.” While this may be true, powerful AI models can potentially infer and use information on gender without explicitly being provided this information. As a result, it is critical to understand how algorithms use information, both directly (through explicitly provided features) or indirectly (through inferred information).

- Model Comparison and Selection
Data scientists often build multiple candidate models to tackle a problem. Typically, they select one model for production use, while other models may be run in benchmark mode. This raises questions about how to compare models and how to select the “best” model.
Accuracy metrics are the current gold standard for selecting models. But, as discussed above, they capture a narrow slice of model quality. This is a major gap in current data science workbenches. Similarly, model comparison is limited currently to statistics on model predictions, such as confusion matrices, which treat the models as black boxes.
Supporting deeper examination of models to understand where and why they differ and how to leverage this information to select and improve models is a pressing need that Model Intelligence technology tackles.
- Monitoring & Reporting
More than traditional models, machine learning models rely on associations in the data that may not hold over time. As a result, when these associations are no longer valid, machine learning models tend to degrade in performance. Current approaches that report on data drift are useful but insufficient to provide the visibility needed by data scientists and other stakeholders to understand and act in the face of changes in data and the world.
It’s critical to understand which associations learned by a model are driving model predictions, shifts in behavior, and performance. Model Intelligence technology supports richer monitoring and reporting that provides this visibility and enables actionable insights to update models and surrounding business rules.
In addition to the key technology challenges, Model Intelligence addresses other problems essential to take models from the bench to the field and to maintain and support their use in production. We briefly touch on a couple of these problems (see Will’s blog post for more details).
- Sharing & Collaboration
Knowledge about ML models is hard to convey. Much of the insights about a model’s quality and its business value is confined to data scientist notebooks and workbenches. This prevents key non-ML stakeholders from building trust in machine learning and collaborating in the process of building and operationalizing them. - Review & Governance
Many industries have developed sophisticated workflows for building trust in models that run their businesses. Specifically, the financial services and insurance verticals have specialized metrics and tools for testing and evaluating their models. In particular, these workflows have been designed with traditional statistical models in mind, in particular, linear models. However, since machine learning models learn more complex relationships and they remain a black box, many of these workflows need to be updated to support the mode review and governance processes.
The Technology Building Blocks of Model Intelligence
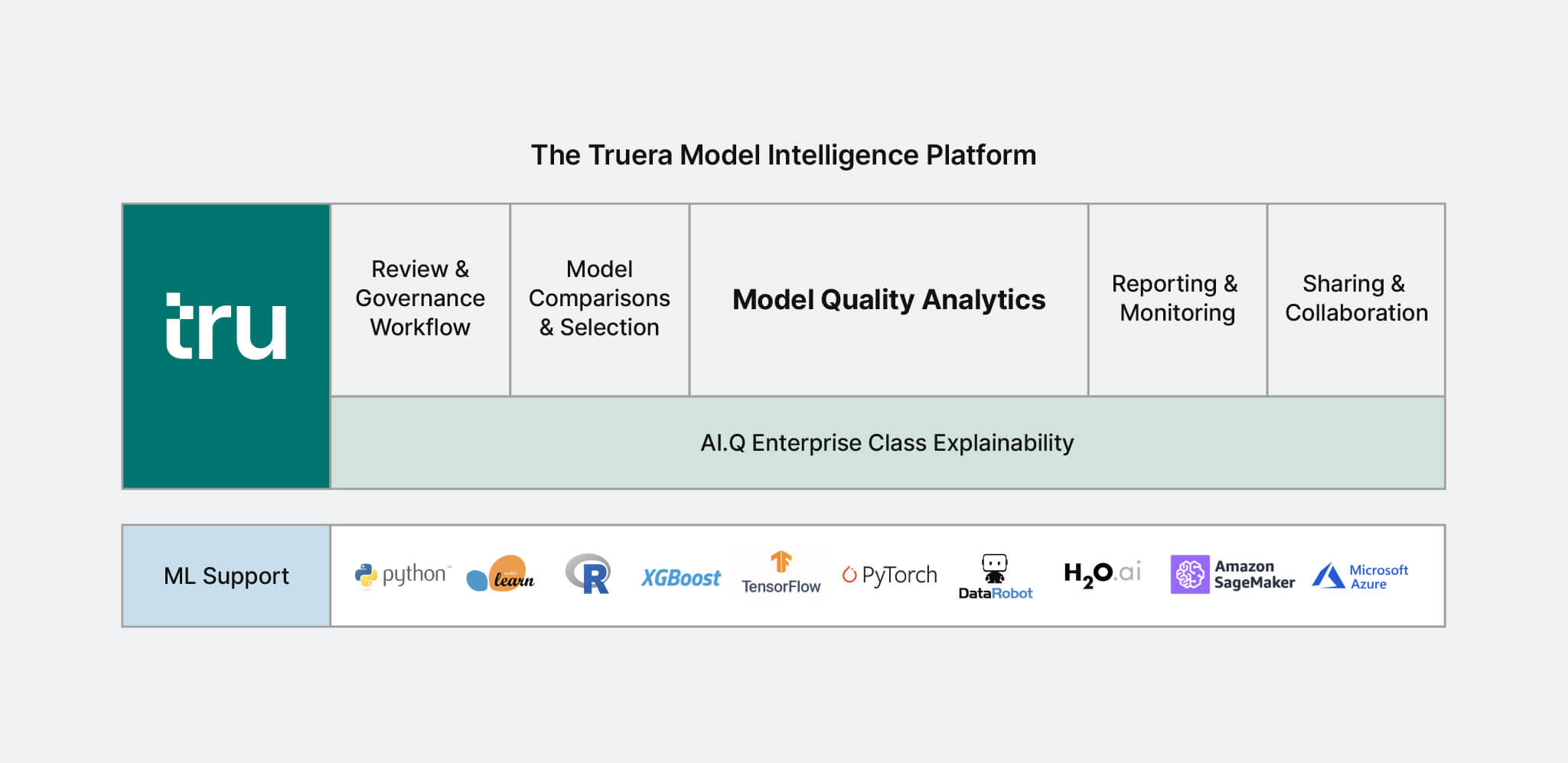
We summarize the key technology building blocks of the Truera Model Intelligence Platform below. Stay tuned for more details.
AI Explainability
Truera’s AI.Q Explainability technology provides a foundation for its Model Intelligence Platform. It performs sophisticated sensitivity analysis that enables data scientists, business users, and risk and compliance teams to understand exactly why a model makes predictions. It is based on our own research at Carnegie Mellon University. Distinctively, AI.Q is model agnostic, answers a rich set of questions about individual and aggregate model predictions, and accurately explains model predictions with confidence bounds and the performance enterprises require.
Model Quality Analytics
Truera’s Model Quality Analytics addresses the problems with evaluating and improving model quality highlighted in the previous section, including model accuracy, fairness and stability. It builds on and significantly expands the core AI.Q explainability technology.
Model Comparisons & Selection
Truera’s platform supports the deep examination of models required to understand where and why a set of candidate models differ and how to leverage this information to improve model quality and select the model with the highest quality. It builds on Model Quality Analytics and expands it to enable operations across models.
Monitoring & Reporting
Truera’s Model Intelligence technology supports rich monitoring and reporting that provides visibility into models and enables actionable insights to update models and surrounding business rules. It provides capabilities to understand which relationships learnt by a model are driving model predictions, shifts in behavior, and performance.
ML Platform Support
Truera’s platform works with ML models built in many popular model development platforms, including open source libraries and proprietary model development platforms, that expose prediction APIs. Its core technology is model agnostic. It also provides a suite of powerful capabilities that leverage additional structure in tree ensemble and deep neural network models.
Our Journey
The Truera story began in 2014 at Carnegie Mellon University. While conducting research, we discovered gender bias in online advertising, but lacked the tools to explain what caused the bias. Passionate about enabling effective and trustworthy artificial intelligence, we dug deeper with colleagues to create a body of work on explainable artificial intelligence.
From the outset, we viewed explainability as a means to guard against societal harms and build higher quality models, i.e. as a building block for what we are now calling Model Intelligence. We were early explorers in this area, part of a growing interdisciplinary community that tackled these challenges and helped raise awareness about them in academic, regulatory and public spheres. In parallel, Will, in his product and business roles at Bloomreach, was experiencing a similar set of challenges with black-box machine learning models and algorithms in enterprises. We joined forces in early 2019 to form Truera.
We have built the Truera Model Intelligence Platform over the past year working with a set of fantastic lighthouse customers (see our case study with Standard Chartered). The challenges faced by our early partners have been a key driver of research and innovation. If you’re a machine learning team with a need for model intelligence, come partner with us.
We are excited about the amazing team building Truera. One of the core cultural principles at Truera is: “Create what’s not there.” We’re building an engineering team of creator-builders who are excited about our mission and keen to build large-scale systems and drive cutting edge research in support of it. Interested in joining us? Check out our Careers page here.