In May 2023, ~15 leading Financial Institutions (including 6 of the top 10 US banks), got together in New York to talk about LLMs. Representatives from first line Data and Analytics/ AI teams, Model Risk, Data Management and analytics-intensive functions spent over 2 hours exchanging notes on the LLM opportunity in the industry, and how to navigate the risks.
The roundtable, organized jointly by TruEra and Quant University, kicked off with short presentations by Agus Sudjianto, EVP and Head of Corporate Model Risk at Wells Fargo, Sri Krishnamurthy, founder of Quant University, and Anupam Datta, co-founder of TruEra and a former professor at Carnegie Mellon University. This was followed by an open, Chatham House rules discussion with all round-table participants. You can download the 4-page summary here: Managing the Risk of LLMs in Financial Services, but here are some key takeaways:
LLM use cases in Financial Services
- The first “killer app” for financial services seems to be internal Q&A – on the organization’s own knowledge corpus
- Text summarization/ translation is an upcoming, adjacent application
- “Traditional” NLP use cases are on steroids with LLMs
- Writing/ reading code appears to be the Next Big Thing
- Appetite for customer-facing use seems limited for now
Risks – New and Existing
- Accuracy/ hallucination concerns are top-of-mind for risk managers
- Security/ Privacy feature heavily with hosted LLMs
- There is uncertainty over IP obligations and rights
- Reputation risk is holding back direct customer use
- Bias will become important with customer-facing use cases
Managing Risks – Model Risk and Beyond
- LLM risk is an end-to-end system risk (not just model risk)
- Most risk managers seem to be in exploratory mode
- Access to embeddings seems essential for Model Validation
- Testing output quality in generative AI is a major challenge
Impact on People, Skills, Ways of Working
- Everyone agrees that the nature of roles will change
- There is less alignment on the extent/ pace of job losses
- “Democratization” of AI will have significant impact
- Will Specialists win over Generalists? Jury is still out
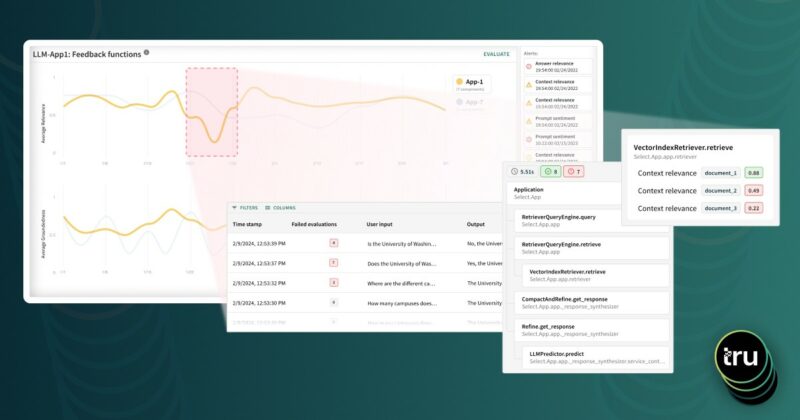
Interested in learning more about testing and debugging LLM applications? Check out TruLens – the first open source library to evaluate and track your LLM experiments, or this blog, explaining the underlying approach.