We’re excited to announce the integration of TruLens with Anthropic to enable anyone to evaluate LLM applications with Claude on the back end. Evaluate your LLM apps to ensure they are honest, helpful and harmless with TruLens feedback functions run with Claude.
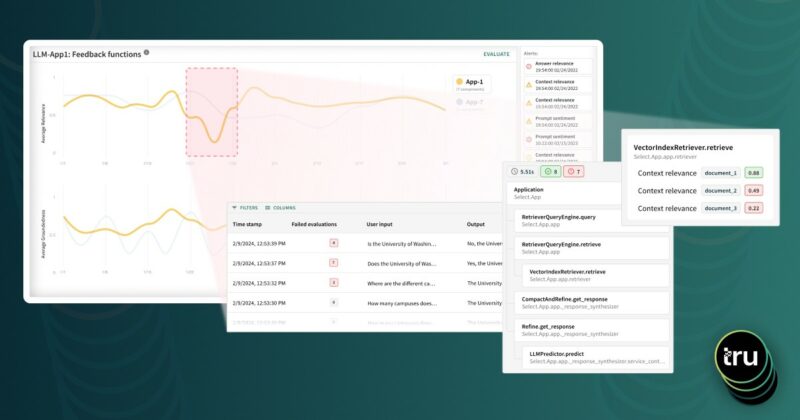
Whether you are building your first prototype or deployed in production, the TruLens observability suite gives you all the evaluations you need to understand its performance.

How do you get started with TruLens and Anthropic?
Using Claude by Anthropic for automated LLM app evaluations is easy. After selecting your model engine as Claude-2 or Claude-Instant, any LLM-enabled feedback function can be integrated to your application.
After we’ve set up feedback function(s) with TruLens and Claude, we can create our recorder by wrapping our LLM application, in this case named chain, and passing in our feedback function(s).
Once we’ve done so, you can use tru_recorder as a context manager for our application. Critically, by using the recorder, every call to your application will now be evaluated by Claude.
How does Anthropic Claude Perform on Evaluation Tasks?
To understand the performance of feedback functions, we ran a set of experiments comparing against a curated set of human evaluations. We ran these experiments on each of the feedback functions commonly used for detecting hallucination: Context Relevance, Groundedness, and Answer Relevance. Last, we also ran these experiments using different backend LLM implementations such as GPT and Claude.
Answer Relevance Performance Results
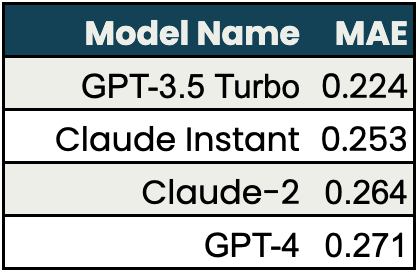
For the task of evaluating the relevance of LLM responses to questions, Claude Instant and Claude 2 performed nearly as well as GPT-3.5-Turbo and better than GPT-4 compared to human evaluations in the test set. The test cases used for answer relevance were generated by the TruLens team to capture a variety of different answer/response pairs. You can find more information about these experiments in our open-source repository.
Context Relevance Performance Results
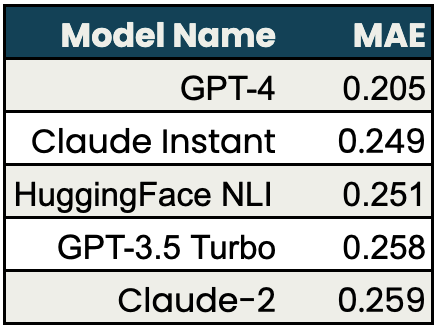
For the task of evaluating the relevance of LLM responses to questions, Claude Instant performed the closest to human evaluations in our test set. The test cases used for context relevance were generated by the TruLens team to capture a variety of different query/context pairs. You can find more information about these experiments in our open-source repository.
Groundedness Performance Results
For the task of evaluating the groundedness of LLM responses based on provided Claude Instant and Claude 2 performed nearly as well as GPT-3.5-Turbo and better than GPT-4. The test cases used for groundedness were generated from SummEval.
SummEval is one of the datasets dedicated to automated evaluations on summarization tasks, which are closely related to the groundedness evaluation in RAG with the retrieved context (i.e. the source) and response (i.e. the summary). It contains human annotation of numerical score (1 to 5) comprised of scoring from 3 human expert annotators and 5 crowd-sourced annotators. You can find more information about this evaluation in our open-source repository.
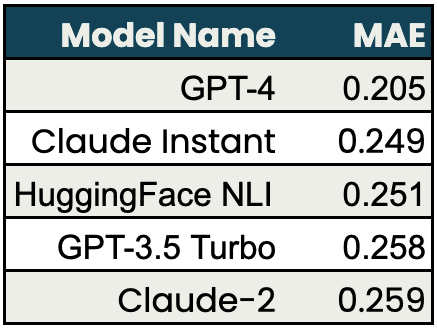
For all three tasks, we find comparable results across the models in our experiments.
Ready to evaluate LLM apps to ensure they are honest, helpful and harmless with TruLens and Claude? Try the Anthropic integration in the notebook below