LlamaIndex is a popular open source framework for building LLM apps. TruLens is an open source library for evaluating, tracking, and iterating on LLM apps to improve their quality. The LlamaIndex and TruLens teams are actively collaborating to enable LLM app developers to rapidly build, evaluate, and iterate on their apps.
In the latest release of TruLens, we introduce tracing for LlamaIndex based LLM applications that allow you to evaluate and track your experiments with just a few lines of code. This lets you automatically evaluate a number of different components of the application stack including:
- App inputs and outputs
- LLM calls
- Retrieved context chunks from an index
- Latency
- Cost and Token Counts
Check out this notebook to get started and read along to get a step by step view.
How do I actually use this?
Build A LlamaIndex App
LlamaIndex lets you connect your data to LLMs and rapidly build applications for a number of different use cases.
Once you build your app, you can easily query your data.
And you get an appropriate response.
Wrap A LlamaIndex App with TruLens
With TruLens, you can wrap LlamaIndex query engines with a TruLlama wrapper. This wrapper preserves all LlamaIndex behavior, but traces all of the intermediate steps so that they can be individually evaluated.
The wrapped app can now be queried in the exact same way:
Except, now the details of the query are logged by TruLens.
Add Feedback Functions
Now to evaluate the behavior of your models, we can add feedback functions to your wrapped application. Note that as a developer you only need to add a few lines of code to start using feedback functions in your apps. You can also easily add functions tailored to the needs of your application.
Our goal with feedback functions is to programmatically check the app for quality metrics.
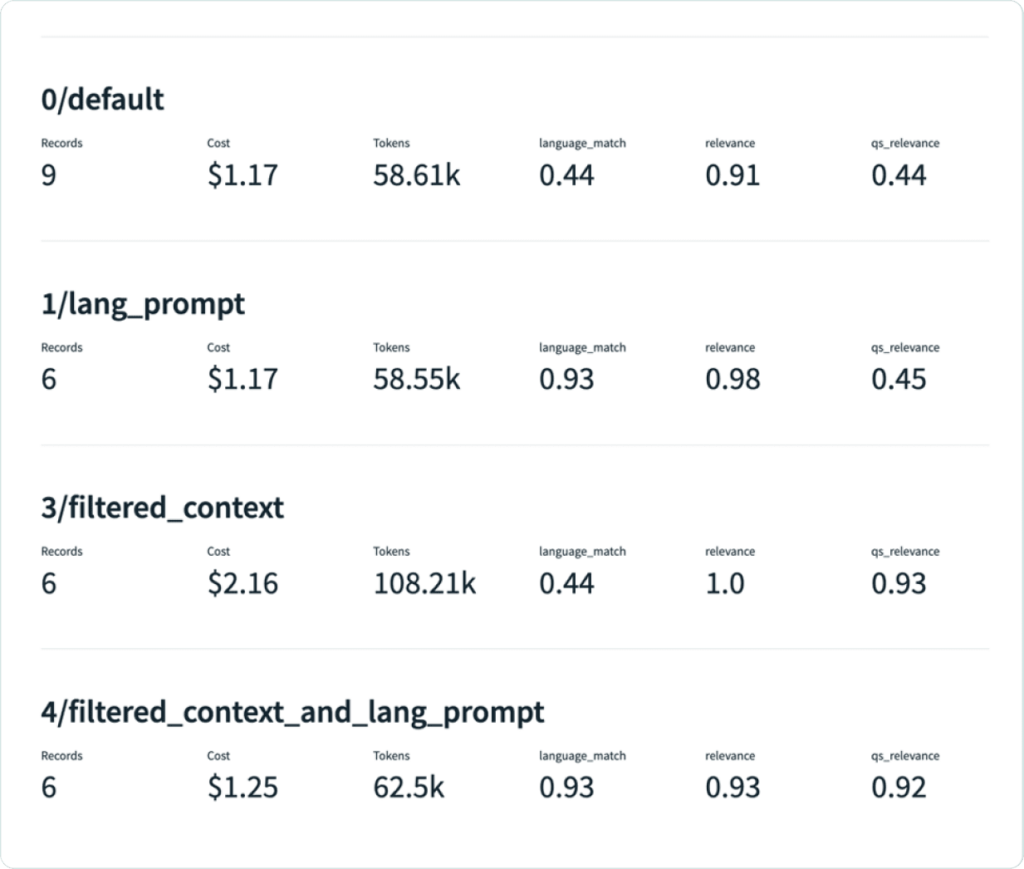
- The first feedback function checks for language match between the prompt and the response. It’s a useful check since a natural user expectation is that the response is in the same language as the prompt. It is implemented with a call to a HuggingFace API that programmatically checks for language match.
- The next feedback function checks how relevant the answer is to the question by using an Open AI LLM that is prompted to produce a relevance score.
- Finally, the third feedback function checks how relevant individual chunks retrieved from the vector database are to the question, again using an OpenAI LLM in a similar manner. This is useful because the retrieval step from a vector database may produce chunks that are not relevant to the question and the quality of the final response would be better if these chunks are filtered out before producing the final response.
Explore In Dashboard
Every query that is tracked can now be viewed in the TruLens dashboard. After running the feedback functions on a set of records (interactions), you can see the aggregate results of the evaluation on a leaderboard; then drill down into an app version and examine how it is performing on individual records. These steps can help you understand the quality of an app version and its failure modes.
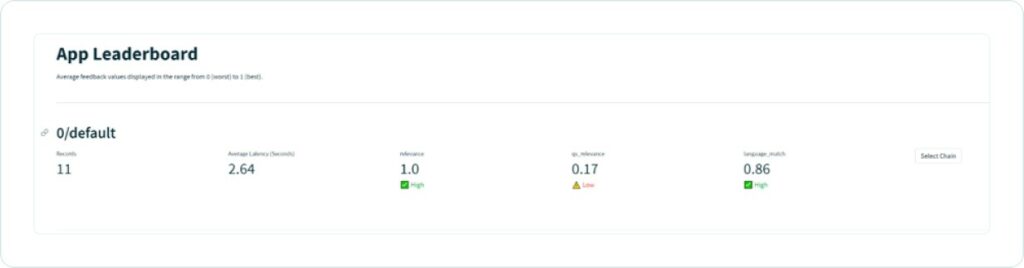
In this example, the model is doing fairly well on the relevance and language match feedback evaluations, but seems to be doing poorly on qs_relevance. This can be an indicator that the retrieved chunks are often irrelevant. This can be a significant source of “hallucinations” in retrieval-augmented generative AI apps.
We can now drill down and identify specific instances where this may be an issue:

Let’s look at a good example first. “What did the author do growing up?”
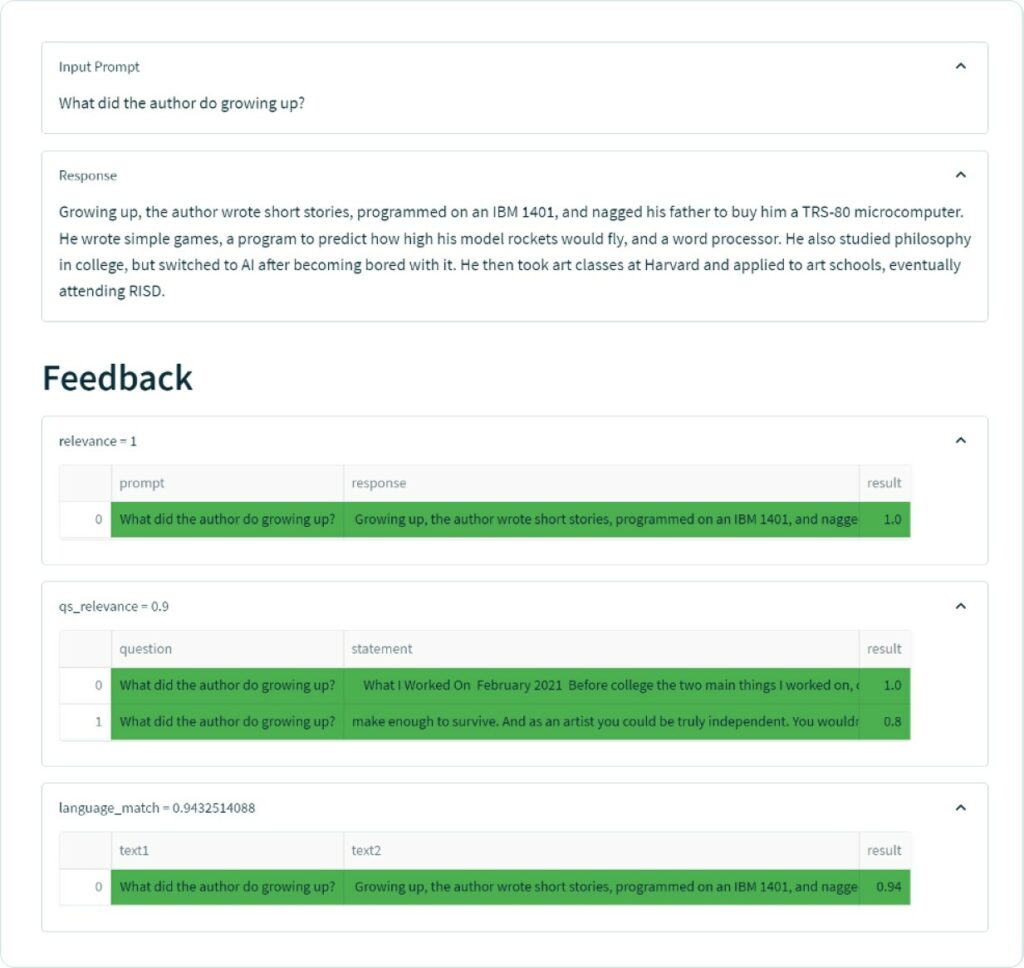
In this example, we retrieved two chunks from the index both of which were fairly relevant to the the question and as a result the LLM summarizes it into a relevant and factually correct answer.
On the other hand, let’s look at an example where this didn’t go so well: “Where was the author born?”. In this example, the app confidently provides an incorrect answer.
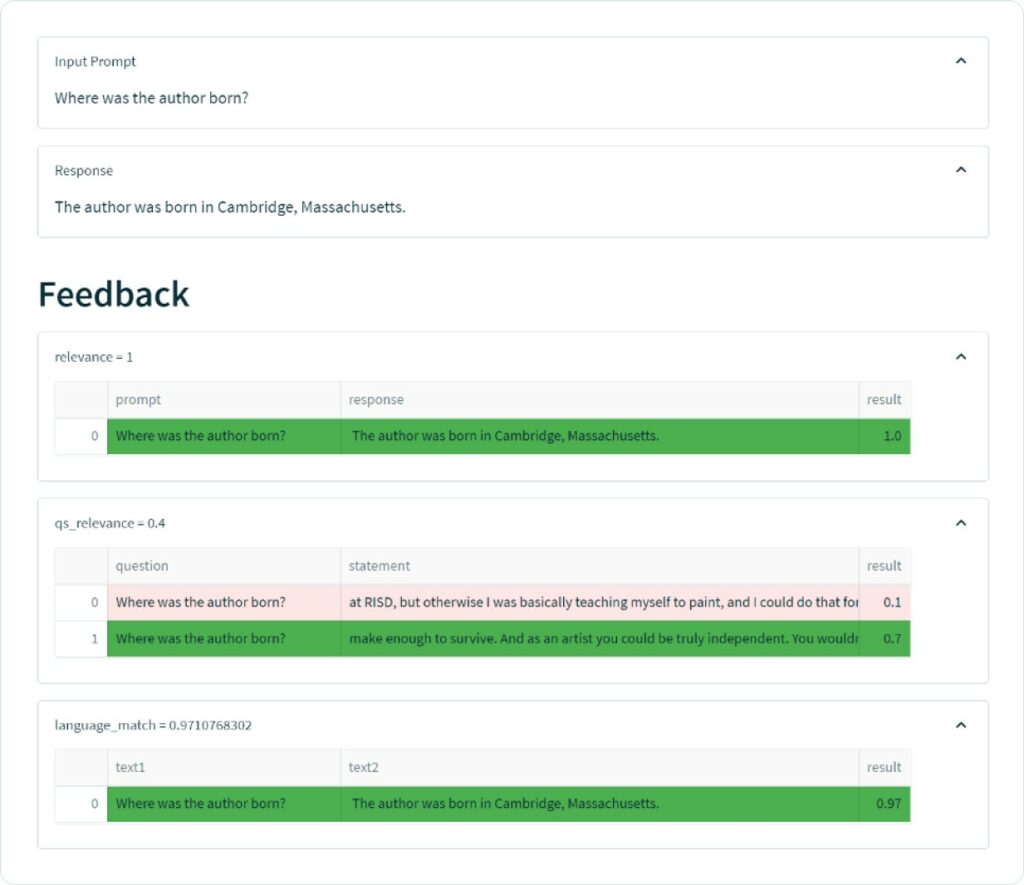
In this example, the two pieces of context retrieved had moderate relevance to the question. Further, neither context contained the answer. Even though our relevance feedback function (which doesn’t check for factual correctness) didn’t detect an issue, because the underlying chunks were not very relevant, this was a strong indicator that something was off. Indeed, this is an example of the model hallucinating on a question that is fairly easy to fact check.
Iterate on your App
Once you find issues like this with your app, it can be helpful to iterate on your prompts, models and chunking approaches to optimize your app. As you do this, you can track the performance of each version of your model with TruLens. Here is an example of a dashboard with multiple iterations testing against each other.