One of the challenges for any software solution is getting it effectively deployed in the customer’s environment, a challenge that has become increasingly difficult as environments become more diverse and more crowded. TruEra is an enterprise-class solution for cloud native companies as well as companies operating on-premises, which some observers might find strange, at first. Look carefully at our customer base, however, and you’ll see that TruEra is trusted by large financial services companies, which operate in heavily regulated industries. One hallmark of regulated industries is that at least some of their data cannot leave on premises data centers, for reasons of data security and consumer privacy. As a result, the deployment solution for TruEra must accommodate cloud, on-premises, and hybrid situations.
When we thought about the right infrastructure for TruEra, we thought about three critical issues to resolve: conflicting compute requirements, minimizing computational cost, and achieving performance consistency on any platform (cloud and on-premises). Let’s dive into how we thought about and solved the challenge to achieve enterprise class performance.
Challenge #1: Resolving conflicting resource requirements
Delivering an effective model intelligence solution requires reconciling some conflicting demands.
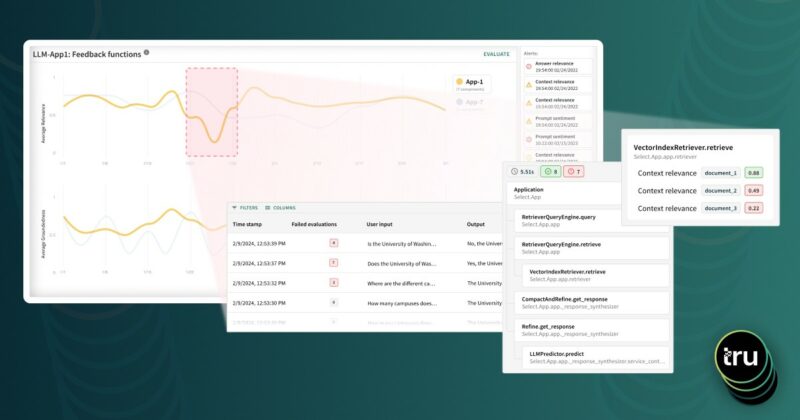
First, let’s understand TruEra’s high level architecture. TruEra has a few kinds of components today: long lived microservices, machine learning model analyzers, and a few flavors of clients – the TruEra command line interface, the TruEra GUI, and Python notebooks. The clients get to the user’s machine via installation packages, pip, or as a web page. This could be its own topic, so let’s concentrate on the first two.
TruEra’s long running microservices and model analyzers have very different resource requirements and properties. The long running services each have a job to do – provide intelligence data to the clients, ingest models and metadata, route network traffic, and so on. Most of them use relatively little memory and cpu, but must be able to get some of both on a continual basis. They are essential to the basic functionality of the tool and must be responsive.
Model analyzers are a different animal. They are spun up on demand when a model needs to be evaluated. They only live for a temporary period while they are doing some predefined work and they know from the beginning what that work will be: evaluate either predictions or feature influences on some model X with input data Y. They do this while giving status updates, then exit. This a cpu and memory intensive process, with the intensity varying based on the amount of data, the model framework, and other factors.
Combining microservices and model analyzers gives us two conflicting sets of requirements: bursts of cpu / memory consumption from model analyzers and services which must get resources for the tool to continue to work. This gives us the strong requirement of resource isolation.
Challenge #2: Minimizing operating and computational costs while maximizing scalability
One outcome of the microservice architecture is that there are many services. Unless the cost per service is low, this imposes a high operating cost to ensure adequate hardware capacity either on premises or from a cloud service provider. If we can keep the cost per microservice low, then the key to a reasonable cost is scaling the model runner resources with the demand.
Model evaluation is very computationally intensive, since it requires running a high volume of simultaneous sensitivity tests to tease out not only how the model is functioning but also how well, across multiple dimensions. At the same time, model evaluation is only occasional. It is not needed consistently over long periods of time. For this reason, the ability to rapidly and efficiently scale the computing footprint up and down is essential to achieving a great customer experience at a reasonable computational cost.
Challenge #3: Running consistently on any platform
There is also one additional requirement – however we deploy our code, it should be reasonably platform agnostic, to accommodate the wide variety of environments that customers operate. To achieve this, we only require a generic version of Linux that can run a relatively recent version of Docker. This relatively easy Linux requirement has shown to be reasonable for enterprises. By not requiring a specific build of a specific distribution, TruEra avoids unnecessary roadblocks when it is deployed to customer data centers.
Containerization emerges as the clear winner
The cross of requirements with rough form factors of solution gives us this table:

Kubernetes is the complete answer
Now that we know that containerization is the correct option to solving the three major challenges, we can refine our solution by considering the secondary requirements.
- First, we’ll need the ability to route network traffic to the correct service and between services. As soon as the services are on separate machines, and may be moved by the scheduling/orchestration layer, routing requests to the correct service becomes a challenge. Kubernetes takes care of all of this network routing.
- We’ll also need to spin up containers for model analyzers dynamically. Since the model analyzers are running in containers in this scheme, we need robust APIs to launch them on demand from within the cluster. Kubernetes has these APIs available.
Kubernetes (k8s) satisfies all of these secondary requirements and has the additional benefits of scaling to thousands of nodes, a rich community that is committed to its technical evolution and success, and the fact that it is already present and trusted on premises at many enterprises.
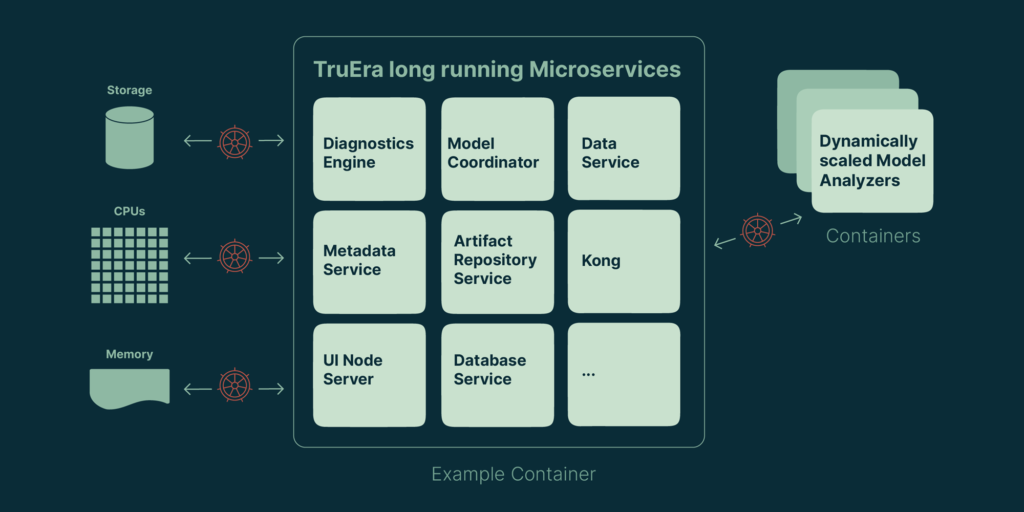
Meeting the needs of the large enterprise
The upshot of the choice of Kubernetes is that we can deploy on any major cloud platform or on premises via solutions like OpenShift. The minimum resource requirement for a cluster deployment is enough resources in a Kubernetes cluster to support the services and a reasonable number of model analyzers. This value is not fixed, but is approximately40 cores, 128 GB of ram and 1 Tb of disk space. This is enough to provide a good experience for a team of a few users, and can be scaled up or down based on the number of users, amount of data, speed and size of models, etc. From this minimum, k8s can support our deployment to well beyond our needs today: Kubernetes supports up to 5,000 machines and 300,000 containers.
What about small deployments?
Kubernetes also brings benefits to smaller deployments. Enterprise class is about reliability, stability, and general scalability, not necessarily customer complexity or massive scale. For deployments with a small number of users, TruEra can utilize a single large VM with all of the services running simultaneously in a single container either within or out of kubernetes. This works for a few users and a few model analyzers. When customers are ready to scale beyond a single machine, TruEra can easily accommodate that growth.
Author
Max Reinsel, ML Infrastructure Engineer